 Lösung
Lösung  Ressourcen
Ressourcen  Preise
Preise  Wissenhub
Wissenhub 







Die Business-KI, die die richtige Antwort zur richtigen Zeit liefert.
Europas führende Business-KI
Eine Plattform für Suche, Assistenz und Automatisierung – ISO-27001 zertifiziert, DSGVO- & EU-AI-Act konform, entwickelt in Deutschland
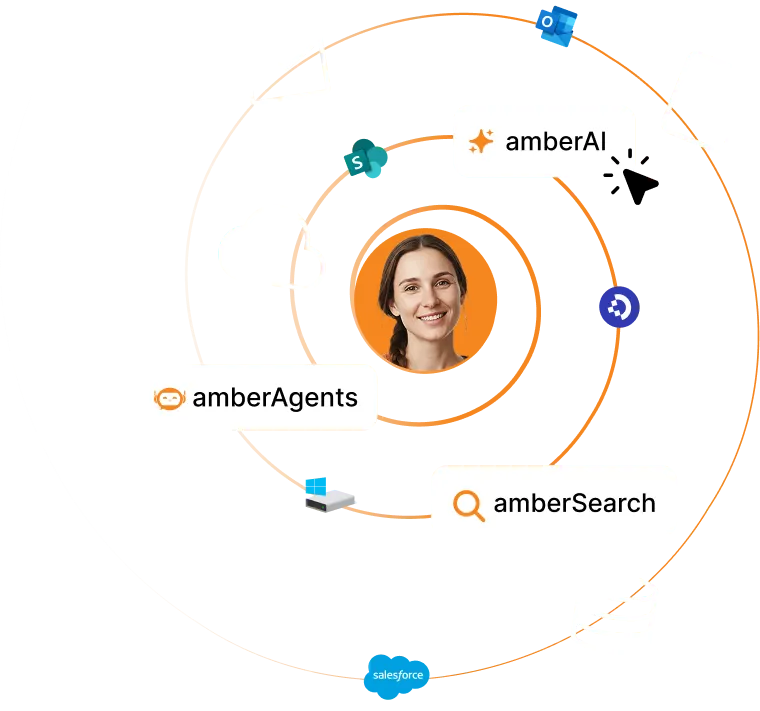
Drei Wege zu intelligenter Wissensnutzung
Von präziser Suche bis zu autonomen Agenten – amber bietet die perfekte KI-Lösung für jeden Anwendungsfall in deinem Unternehmen.

Finde Antworten in Sekunden – präzise, kontextgenau, sicher.

Dein FirmenGPT – fundiert statt generisch.

Baue spezialisierte Agenten für wiederkehrende Aufgaben & Workflows.
Über 400 führende Unternehmen vertrauen amber







Bewährte Methoden versagen - neue Zeiten brauchen neue Antworten
Über 6 Mio. Fachkräfte gehen bis 2030 in Rente und nehmen ihr Wissen mit. Gleichzeitig explodiert die Datenmenge täglich. amber macht dein Unternehmen & dein Wissen mit KI zukunftssicher.

Explodierender Informationsüberfluss
Täglich entstehen neue Dokumente, E-Mails und Daten – aber keiner hat mehr einen Überblick.
alle 2 Jahre
verdoppelt sich die Datenmengen in Unternehmen

Verlorenes Know-how durch Demografiewandel
Erfahrene Mitarbeitende gehen in Rente und nehmen ihr Wissen mit – unwiederbringlich.
6 Mio Renteneintritte bis 2030
Laut Statista

Unsichere Schatten-IT
Mitarbeitende nutzen ChatGPT & Co. für interne Daten – ein Sicherheitsrisiko für Ihr Unternehmen.
Bis zu 85%
der Mitarbeitenden nutzen KI-Tools, welche nicht freigegeben sind
amberSearch - die KI-Suche für deine internen Daten
Finde Antworten in Sekunden – über alle internen Datenquellen hinweg, auch bei exponentiellem Datenwachstum.
- Intelligente, systemübergreifende Suche auch in den Inhalten der Dokumente
- Inkl. generierter Zusammenfassung auf Basis der gefundenen Informationen
- Berücksichtigt alle bestehenden Zugriffsrechte
amberAI - der KI-Assistent für deine Mitarbeitenden
Lasse dir Wissen in dem Format aufbereiten, wie du es benötigst. Genauso flexibel wie deine Anwendungsfälle. Durch amberSearch wird internes Wissen genutzt.
- Multi-LLM-Unterstützung für optimale Ergebnisse
- Upload-Funktion - arbeite mit allen relevanten Inhalten
- Native Integration in bestehende Nutzeroberflächen
amberAgents - KI-Agenten für wiederkehrende Aufgaben
Automatisiere deine wiederkehrenden Aufgaben und Prozesse mit unseren KI-Agenten - einfach integrierbar und skalierbar.
- Vorgefertigte Agentenvorlagen für sofortige Nutzung
- Nutzt aktuelles Wissen durch KI-Suche
- Individuelle Instruktionen und Anpassungen

Von Anfang an begleitet: Schritt-für-Schritt zum KI-Erfolg
Unsere Schritt-für-Schritt Playbooks und Customer-Success-Teams sorgen für schnelle, sichere Einführung und nachhaltige Nutzung.
- Begleitete Einführung ohne Risiko
- Iterativer Schritt-für-Schritt Roll-out
- Unterstützung beim Aufsetzen der KI-Agenten
Bereit für effizienteres Arbeiten?
Starte noch heute und erlebe, wie amber dein Unternehmenswissen sofort verfügbar macht – sicher und DSGVO-konform.
Wie sich bereits über 400 Unternehmen mit amber zukunftssicher aufstellen
Von Mittelstand bis Konzern – deutsche Unternehmen stellen sich mit amber für die Zukunft auf
"Wir haben mit amberSearch mehrere Chatbots zu sehr konkreten Wissensbereichen im Unternehmen entwickelt; von Tool-Support-Bots bis Wissensträger zu allen internen News. Die intuitive Bedienung und die schnelle Rückkopplung machen solche Entwicklungen einfach und schnell. Inzwischen nutzt eine Vielzahl unserer Kolleginnen und Kollegen amberSearch in ihrem Alltag. "

"Als breit aufgestellter Immobilienprojektentwickler mit über 200 Mitarbeitenden in der gesamten Unternehmensfamilie gibt es immer gleich mehrere Teams verschiedener Bereiche, die parallel an einem Projekt oder Thema arbeiten. In den vergangenen Jahren kam hinzu, dass wir stark gewachsen sind und fortlaufend Prozesse digitalisiert haben. Dadurch wurde es zunehmend schwieriger, Wissen über Projekte und Strukturen einfach und für alle zugänglich zu machen. Mit amberSearch gelingt uns, unser Know-How, Daten und Dateien über diverse Plattformen hinweg intuitiv auffindbar zu machen. Dadurch sparen wir nicht nur Zeit und Ressourcen, sondern fördern auch die Zusammenarbeit und Effizienz in der gesamten Unternehmensgruppe. "

"Die ENTECCOgroup ist aus mehreren mittelständischen Unternehmen entstanden. Daraus entstand die Herausforderung, die verschiedenen Informationssysteme und Informationen zu zentralisiere, um diese allen Mitarbeitenden zugänglich zu machen. Mit amberSearch konnten wir mit wenig Aufwand die verschiedenen Datentöpfe für alle Mitarbeitende zugänglich machen, ohne alle Daten neu- oder umspeichern zu müssen. Dadurch können wir z. B. Gewährleistungsansprüche oder Rückfragen zu früheren Projekten deutlich schneller bearbeiten. "

"Als mittelständischer Maschinenbauer sind sehr viele Mitarbeitende schon lange Teil des Teams. Über die Jahre haben wir sehr viele komplexe Projekte durchgeführt und dabei eine Menge Know-How aufgebaut. amberSearch integriert all unsere relevanten Systeme und ermöglicht uns, auch die Details aus älteren Projekten zu finden. Darüber hinaus hilft amberSearch speziell den neuen Kollegen, sich schnell in unsere Prozesse und Projekte einzuarbeiten. "

"Als international agierendes Unternehmen wurden unsere Informationen über Jahre in verschiedenen Systemen und Sprachen gespeichert, was ihre Wiederverwendung erschwerte. Mit der KI-Software von amberSearch, die intern den Namen „zGPT“ trägt, haben wir nun zentralen Zugang zu unserem Unternehmenswissen. Dies ermöglicht uns, Fachwissen effizient zu nutzen, innovative Produkte zu entwickeln und unsere Wettbewerbsfähigkeit zu steigern. "

In 3 Schritten zu deiner Business-KI
Europas führende Business-KI, die dein Unternehmen heute stärkt – und für morgen vorbereitet

Einfach Starten
30 Tage kostenlos testen
Starte direkt mit vorgefertigten KI-Agenten für deine Anwendungsfälle und lade dein Team zur gemeinsamen Evaluation ein. Integriere eigenes Wissen durch manuellen Upload wichtiger Dokumente. Profitiere von unserem individuellen AI-Onboarding für eine optimale Einführung.
Ziel: Erste wertvolle Erfahrungen mit KI sammeln und das Potenzial für dein Unternehmen entdecken.

Integrieren
amber Professional, Business oder Enterprise
Binde dein internes Wissen über unsere Konnektoren ein – egal ob Cloud oder On-Prem-Systeme. Deine bestehenden Zugriffsrechte bleiben dabei automatisch erhalten.
Ziel: So wird KI wirklich zum Zugangstor für dein gesamtes Unternehmenswissen.

Verankern & Verstärken
für die nachhaltige Integration
Nutze amber als täglichen Begleiter: suchen, chatten, Aufgaben automatisieren. Mache Wissen nachhaltig nutzbar – amber verankert sich direkt in deinem Workflow.
Ziel: Nachhaltiger Nutzen, steigende Produktivität und Zukunftssicherheit.
amber bietet alles, was Unternehmen in einer professionellen Business KI benötigen
Entdecke unsere wichtigsten und leistungsstärksten Funktionen, mit denen wir Unternehmen helfen sich zukunftsfähig aufzustellen
Berücksichtigung interner Zugriffsrechte
Generierte Antworten werden nur auf Basis der in den verschiedenen Systemen vergebenen Zugriffsrechten angezeigt
Enterprise-Security
Vollständig konform mit allen wichtigen Standards: ISO27001-zertifiziert, DSGVO- & EU-AI-Act konform, SOC2-konform
Optional: Deployment auf eigenen Ressourcen
Hosting in der eigenen Infrastruktur möglich (hohe Hardwareanforderungen)
Steuerung durch interne IT-Abteilung
Zentrale Firmen-KI unter Kontrolle der eigenen IT-Abteilung. Strukturierter Roll-Out auf Basis interner Zugriffs- und Rechtegruppen – Schatten-IT wird vermieden
Hosting in Deutschland
Hosting auf sicheren Servern in Deutschland. Hosting auf der Open Telekom Cloud.
SSO & Entra ID
Authentifizierung via SSO oder Entra ID (Sicherer Log-In gemäß internen IT-Standards)
Nachvollziehbare Antworten
Generierte Antworten werden referenziert mit Link zur richtigen Stelle und Highlighting im Dokument
Kein Training mit Kundendaten
KI-Modelle werden nicht mit Kundendaten trainiert sondern stattdessen vollkommen DSGVO-konform bereitgestellt.
Warum amber der perfekte Partner für deine BusinessKI ist
Erfahrung, technologische Basis und nachweisbare Erfolge – das macht uns zu deinem vertrauenswürdigen Partner für KI-Innovation.

Pioniere seit 2020
Bereits 2020 – lange bevor KI zum Hype wurde – haben wir mit unserer unternehmensinternen KI-Suche amberSearch den Grundstein gelegt. Als Team mit Erfahrung im Mittelstand und RWTH-Hintergrund verstehen wir die spezifischen Herausforderungen von Wissensarbeitern und dem Mittelstand.

Fundamentale Differenzierung
Während andere KI-Plattformen erst seit 2023 mit uploadbasierten Chatbots angefangen haben, haben wir von Anfang an auf nahtlose Integration gesetzt. Unsere Lösung respektiert bestehende Zugriffsrechte und verwandelt dein Unternehmenswissen in präzise, individuelle Antworten.

Über 400 erfolgreiche Implementierungen
In über 400 Unternehmen haben wir bewiesen: KI funktioniert nicht nur technisch, sondern vor allem mit den Menschen. Unsere Software ist darauf ausgelegt, Mitarbeitende dort abzuholen wo sie stehen und den Arbeitsalltag spürbar zu vereinfachen.
Europas führende Business-KI
Unsere Vision: Europas führende Business-KI zu werden. Wir kombinieren bewährte Innovation mit europäischer Compliance und echtem Kundenfokus. amber stärkt dein Unternehmen heute – und macht es fit für morgen.
Bereit für die Zukunft der Business-KI?
Erlebe selbst, warum über 400 Unternehmen auf unsere Expertise vertrauen. Starte noch heute und entdecke das Potenzial für dein Unternehmen.