 Lösung
Lösung  Ressourcen
Ressourcen  Preise
Preise  Wissenhub
Wissenhub 


 Unternehmen
Unternehmen 



Um unternehmensinterne Inhalte zu durchsuchen, wird typischerweise eine Enterprise Search genutzt. Doch die Architektur der Suche beeinflusst auch die Qualität, die Möglichkeiten der Weiterentwicklung sowie die Zukunftsfähigkeit des jeweiligen Enterprise Search Systems. In diesem Blogartikel geht es darum, die verschiedene Architekturen zu erklären sowie die technischen Unterschiede aufzuschlüsseln.
Insbesondere werden dafür die drei verbreitesten Architekturen von Enterprise Search Lösungen am Markt begutachtet. Diese sind Federated Search, Keyword-based Search sowie die auf Large Language Modellen (LLM) basierte intelligente Suche.
Inhaltsverzeichnis
Wie funktioniert eine Keyword-basierte Suche?
Keyword-basierte Suchen sind in der ursprünglichen Form die simpelste Form der Enterprise Search. Diese Technologie erlebte jedoch insbesondere in den 90er bzw. 2000er Jahren einen wahren Push, da zu dieser Zeit erstmalig große Datenmengen händelbar waren. Dies funktioniert über einen Index, der neben Informationen aus dem Text auch Metadaten, URL’s und Co enthalten kann. Eine Keyword-basierte Enterprise Search funktioniert nach dem folgenden Prinzip:
- Zuerst werden alle verfügbaren Datenquellen innerhalb des Unternehmens erfasst, einschließlich interner Dokumente, Datenbanken, E-Mails, Intranetseiten und mehr. Diese Daten werden dann indexiert, was bedeutet, dass Schlüsselwörter und Metadaten aus den Dokumenten extrahiert und in einer durchsuchbaren Datenbank – dem Index – gespeichert werden.
- Wenn ein Benutzer eine Suchanfrage stellt, gibt er in der Regel Schlüsselwörter oder Phrasen ein, um nach spezifischen Informationen zu suchen. Diese Suchanfrage wird von der Enterprise Search genutzt, um im Index nach Treffern zu suchen.
- Um die Relevanz der Treffer zu bewerten, werden verschiedene Faktoren berücksichtigt. Hierzu zählen Faktoren wie die Häufigkeit der Schlüsselwörter im Dokument, die Position der Schlüsselwörter im Dokument sowie Informationen aus Metadaten.
- Die relevantesten Dokumente werden in den Suchergebnissen angezeigt, normalerweise sortiert nach der algorithmisch berechneten Relevanz. Die Benutzer können die Suchergebnisse durchsuchen und auf diejenigen Dokumente zugreifen, die ihren Anforderungen am besten entsprechen.
Die meisten Keyword-basierten Enterprise-Search-Lösungen bieten zusätzlich Filter- und Facettenoptionen, mit denen Benutzer die Suchergebnisse weiter einschränken können. Dies kann beispielsweise nach Datum, Dokumententyp, Autor und anderen Kriterien erfolgen. Seit einigen Jahren können Keyword-basierte Suchen mit Technologien wie Natural Language Processing erweitert werden, um die Ergebnisse zu verbessern. Dazu können bspw. Thesauren genutzt werden, um Normalisierungen von Wörtern sowie Synonyme für die Suchmaschine erkennbar zu machen. Nutzt man diese Techniken in Keyword-basierten Suchen, dann erhält man bereits Suchalgorithmen, die mit einer gewissen Semantik umgehen können.
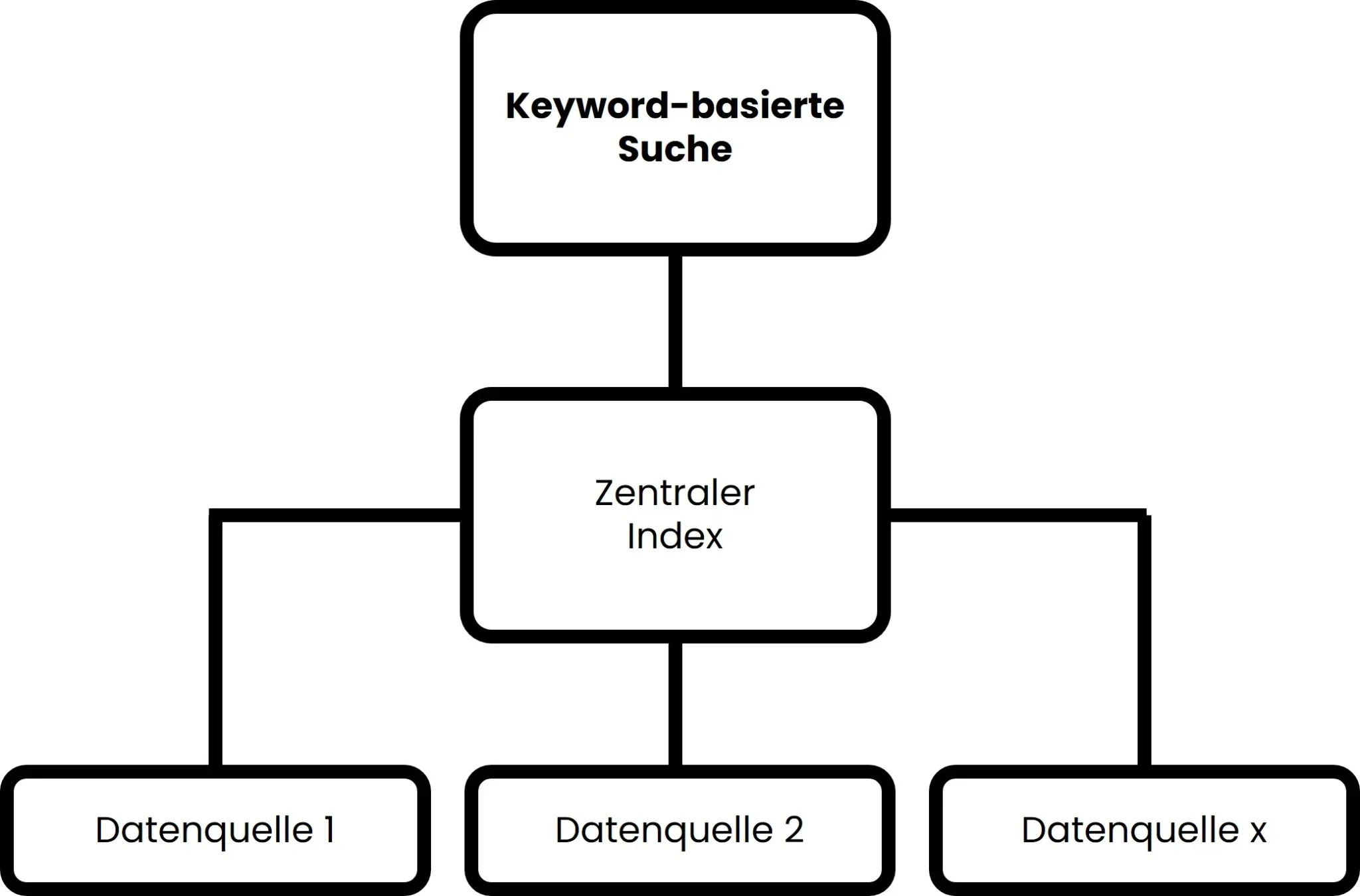
Abbildung 1 – Darstellung der Logik einer Keyword-basierten Suche
Challenge:
Eine Keyword-basierte Suche ist stark abhängig von den verwendeten Schlüsselwörtern. Daher muss der Nutzer schon wissen, wonach er sucht, um relevante Ergebnisse zu bekommen. Zusätzlich wird der Kontext der Sucheingaben (bspw. wer sucht, was hat Nutzer zuletzt gesucht, …) nicht berücksichtigt. Dies kann dazu führen, dass möglicherweise unvollständige Ergebnisse angezeigt werden. Eine große Abhängigkeit der Ergebnisqualität besteht zudem von der Qualität der einpflegten Synonyme. Zusätzlich muss zunächst der Index aufgebaut werden. Die Berücksichtigung von Zugriffsrechten ist – das gilt übrigens bei allen Suchen – nicht ganz trivial. Einige Anbieter bieten eine Berücksichtigung von Zugriffsrechten an, bei anderen wird die Suchfunktion ausschließlich auf im Unternehmen für alle zugängliche Informationen beschränkt.
Vorteile:
Der Vorteil einer Keyword-basierten Suche liegt für den Nutzer darin, dass er seit Jahren im unternehmensinternen Kontext daran gewöhnt ist, mit dieser (bzw. leicht abgewandelten Syntax) zu arbeiten. Mit einer mit semantischen Elementen kombinierten Keywordsuche kann man, abhängig vom Anwendungsfall, bereits gute Ergebnisse erzielen.
Wer überlegt, generative KI-Technologien in seinem Unternehmen einzusetzen, der sollte vorher unser kostenloses, 16-seitiges White Paper mit allen notwendigen Insights lesen: “So geht eine erfolgreiche Einführung von Enterprise Search in Kombination mit generativer KI”
Wie funktioniert eine Federated Search?
Die Federated Search ist aus heutiger Sicht die einfachste Form der Enterprise Search. Um die systemübergreifende Suche zu ermöglichen, wird nämlich kein eigener Index aufgebaut. So funktioniert eine Federated Search:
- Zunächst wird ein Front End für den Nutzer entwickelt, über welches er eine Suche eingeben kann.
- Wenn ein Benutzer eine Suche eingibt, werden im Hintergrund die eingegebenen Wörter Eins zu Eins an die Suchmaschinen aller angebundenen Systeme gegeben. Jede Suchmaschine sucht mit der eigenen Logik im jeweiligen systeminternen Index.
- Die von den jeweiligen Suchmaschinen gefundenen Ergebnisse werden an die Federated Enterprise Search wiedergegeben. Diese durchmischt die Ergebnisse nun nach einer eigenen Logik oder zeigt die Ergebnisse einfach sortiert nach den verschiedenen Datenquellen an.
Der Prozess ist beispielhaft in Abbildung 2 dargestellt.
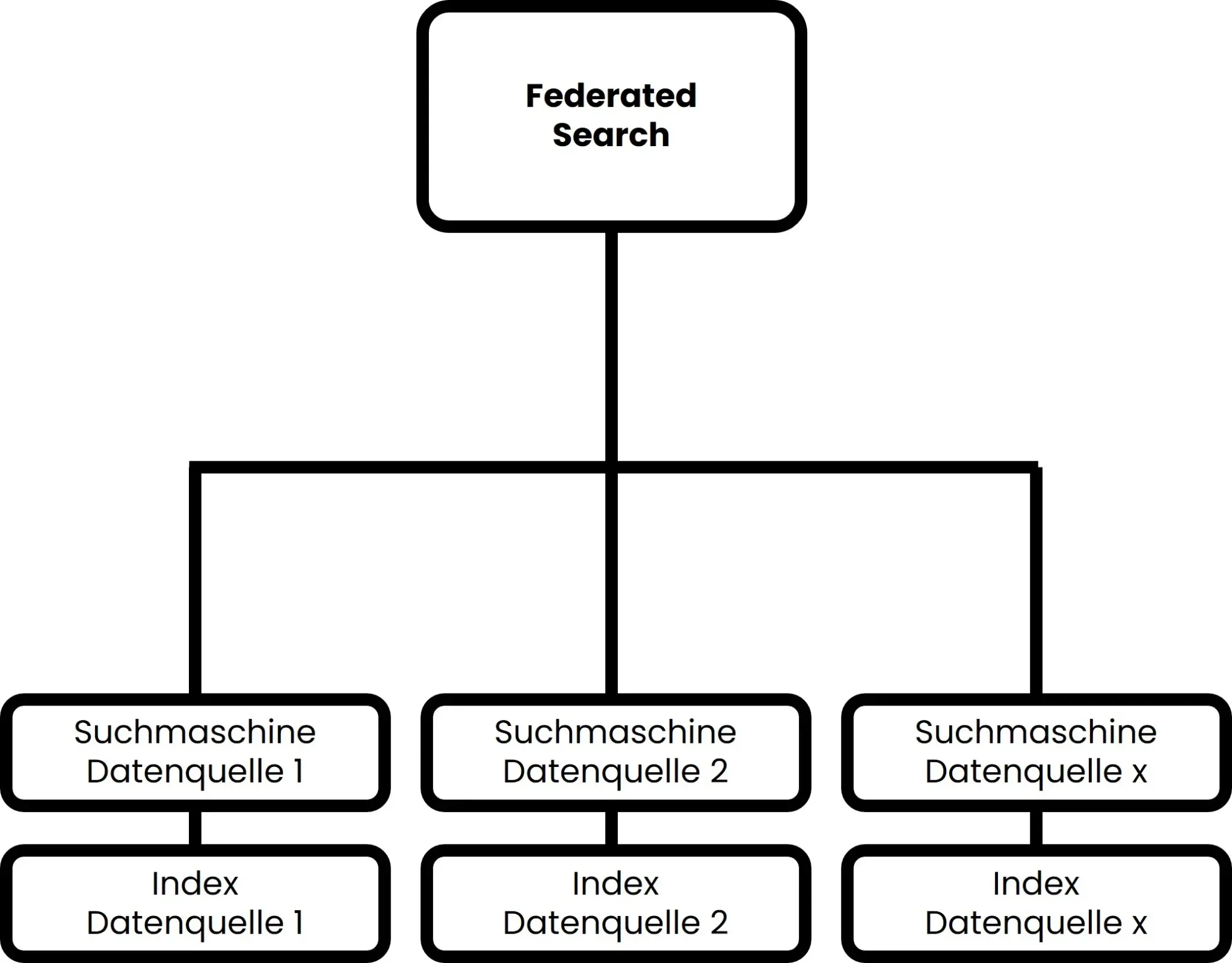
Abbildung 2: Darstellung der Logik einer Federated Search
Challenges:
Dadurch, dass die Federated Search von der Qualität der Suchmaschinen der jeweiligen Datenquellen abhängt, wird ein Enterprise Search Anbieter, der diese Technik verwendet, die Qualität der Ergebnisse der einzelnen Systeme nie schlagen. Es gilt: Wenn die Ergebnisse einzelner Suchmaschinen schlecht sind, dann wird auch eine Enterprise Search nicht in der Lage sein, diese zu verbessern.
Die Challenge besteht nämlich darin, dass eine Federated Search die für die jeweilige Suchmaschine (bspw. E-Mailsuche vs. CRM vs. Laufwerksuche) benötigte Syntax nicht berücksichtigt.
Eine weitere Challenge besteht darin, dass die Suche von den Suchgeschwindigkeiten der jeweiligen Systeme abhängt und diese auch nicht beschleunigen kann.
Zuletzt ist das Matching der verschiedenen Nutzeraccounts nicht ganz trivial. Es ist sicher zu stellen, dass ausschließlich Nutzerergebnisse aus Sicht des Nutzers gezeigt werden und keine „Administratorenaccounts“ Accounts für die Suche genutzt werden, die auf alles Zugriff haben – dann sähe der Nutzer auch alles.
Vorteile:
Der Vorteil der Federated Search liegt darin, dass Sie die simpelste Architektur hat und mit verhältnismäßig geringem (Hardware-)Aufwand installiert werden kann. Zusätzlich erhält man alle Ergebnisse in einer Oberfläche.
Das Model Context Protocol
2024 wurde von Anthropic das sogenannte Model Context Protocol vorgestellt. Das Model Context Protocol ist eine Möglichkeit, um KI-Anwendungen mit Unternehmenswissen zu verbinden und basiert im Kern auf den gleichen Ansätzen wie eine Federated Search. Allerdings hat auch der MCP-Ansatz einige Schwächen, über die wir in diesem Blogartikel aufklären.
Du findest unseren Content spannend?
Dann bleib jetzt über unseren Newsletter mit uns in Kontakt:
Wie funktioniert eine intelligente Suche?
Die intelligente Suche, so wie wir sie definieren, funktioniert auf Basis von Large Language Modellen (LLM), bzw. Transformermodellen, um genau zu sein. Es gibt einige Anbieter, die bereits eine mit NLP-kombinierte, Keyword-basierte Suche als intelligent bezeichnen, daher ist bei der Betrachtung verschiedener Anbieter ein genauer Blick notwendig, um die Unterschiede zu erkennen. Transformermodelle wurden zunächst 2017 auf der NIPS von Google vorgestellt. Durch Künstliche Intelligenz bieten Transformermodelle eine vollkommen neue Technik, um nach Informationen zu suchen. Im Gegensatz zur Keyword-basierten Suche fokussiert sich die intelligente Suche primär auf die semantische Bedeutung von Sätzen bzw. Absätzen, anstatt sich ausschließlich auf Stich- oder Schlüsselwörter zu fokussieren. Und so funktionierts:
- Ähnlich wie bei einer Keyword-basierten Suche wird auch für die intelligente Suche ein eigener Index aufgebaut. Jedoch werden die Informationen dabei nicht nur in einer einfachen Datenbank abgelegt, sondern in sogenannten Vektorembeddings. Dadurch werden Informationen auf Basis ihrer semantischen Bedeutung abgelegt. Dies geschieht durch den in Abbildung 3 gezeigten Embedding Generator. Zusätzlich wird (zumindest bei amberSearch) der vektorbasierte Index teilweise durch einen klassischen Index ergänzt.
- Wenn ein Benutzer eine Suchanfrage stellt, kann er entweder Schlüsselwörter oder auch Fragen in natürlich Sprache eingeben. Die Suchanfrage wird dann ebenfalls in ein Vektorembedding umgewandelt, damit der semantische Sinn verstanden werden kann.
- Die gefundenen Vektorembeddings werden durch die Suchsoftware analysiert und die Ergebnisse basierend auf verschiedenen Faktoren wie der inhaltlichen Relevanz gematched. Dabei werden nicht nur exakte Übereinstimmungen gematched, sondern auch verwandte Konzepte und Themen (s. Abbildung 4).
Der Prozess ist in Abbildung 3 dargestellt:
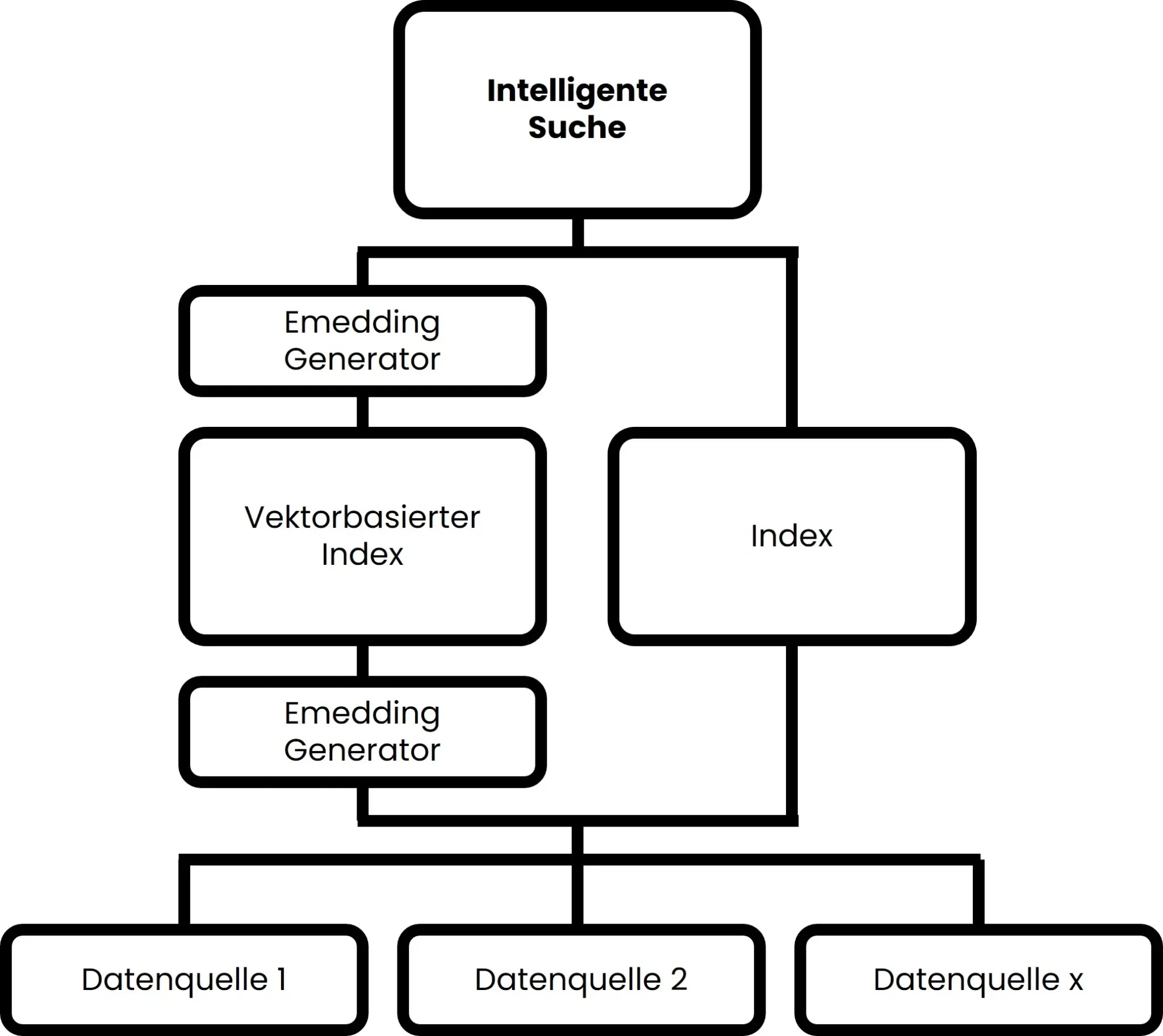
Abbildung 3: Darstellung der Logik einer intelligenten Suche
Challenges:
Dadurch, dass die Bewertung der Ergebnisse mit Hilfe eines KI-Modells vorgenommen wird, ist die Verwendung einer intelligenten Suche rechenintensiver und erfordert leistungsstärkere Server als die anderen vorgestellten Techniken. Zusätzlich ist einiges an Know-How notwendig, um ein solches System aufzusetzen und die verschiedenen Schritte optimal aufeinander abzustimmen.
Vorteile:
Die Ergebnisse werden deutlich unabhängiger von der Art, wie die Suchanfrage gestellt wird. Durch die verwendete Technik kann insbesondere auf den vom Nutzer gemeinten Inhalt eingegangen werden. Zusätzlich funktioniert eine semantische Suche unabhängig von der Sprache, d. h. es kann zeitgleich in verschiedenen Sprachen gesucht werden. Aufgrund der neuen Suchtechnologie ist nicht mit Geschwindigkeitsverlusten, wie bei älteren Keyword-basierten Suchen zu rechnen. Über den vektorbasierten Index können zusätzlich multimediale Inhalte wie bspw. Bilder, Videos, 3D-Modelle oder Audiodateien abgebildet werden, sodass deutlich mehr Inhalte als ausschließlich Textinhalte durchsucht werden können. Das folgende Beispiel soll die Suchlogik einer intelligenten Suche, die auf LLM’s basiert, verdeutlichen:
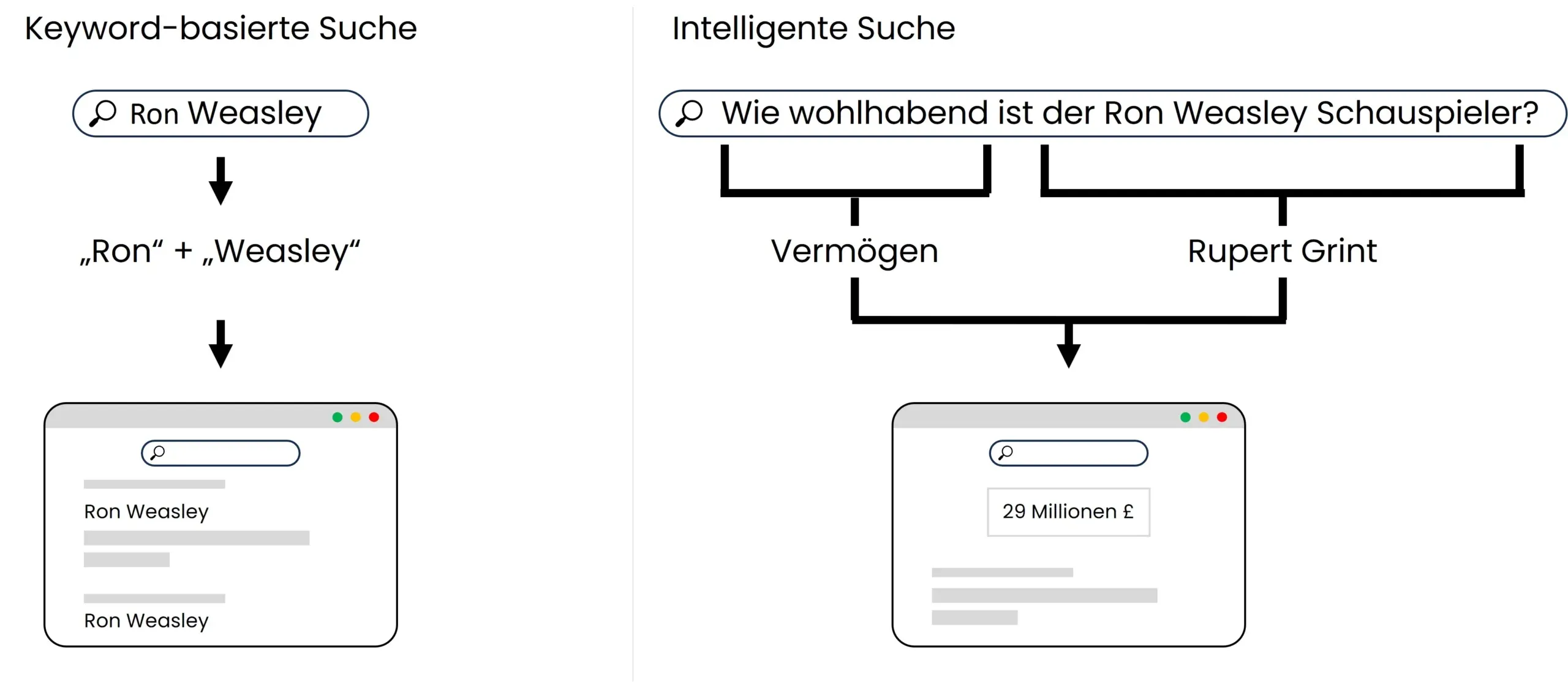
Abbildung 4: Vergleich Suchlogik Keyword-basierte Suche vs. intelligente Suche
Abbildung 4 zeigt die Unterschiede der Suchlogik einer Keyword-basierten sowie einer intelligenten Suche. Bei der Keyword-basierten Suche geht es vor allen Dingen um die Häufigkeit und Positionierung gewisser Worte, bei der semantischen Suche auf der rechten Seite geht es vor allen Dingen um das Verständnis der Inhalte.
In unserer Onlinedemo haben wir eine mittlere sechsstelligen Anzahl an Dokumenten in über 10 Systemen hinterlegt, damit interessierte ein Gefühl für amberSearch bekommen können:
Einsatz einer intelligenten Suche bei amberSearch
Schon im Jahr 2020 haben wir bei amberSearch das Potenzial der semantischen Suche erkannt. Daher haben wir 2020 das zum Zeitpunkt der Veröffentlichung effizienteste, deutschsprachige LLM entwickelt und Open Source gestellt. Darauf aufbauend haben wir ein multlinguales Passage Reranking Modell entwickelt, welches bis heute weit über 200.000 Downloads erhalten hat und in diversen Papern als effizientes KI-Modell seiner Art eingestuft wurde (s. Quellen in unserem Blogbeitrag Retrieval Augmented Generation). Somit setzen wir also auf eigenes Know-How. Intern sind wir mittlerweile mehrere Iterationen weiter, doch auch die aktuellen Downloadzahlen sprechen für die Qualität des Modells. Der frühe Einsatz dieser Technologie hat uns ermöglicht, als eines der ersten deutschen Unternehmen Know-How in diesem Bereich aufzubauen. Dieses Know-How haben wir genutzt, um diese Technologie zur Marktreife in unserem Produkt amberSearch zu bringen.
Grundlagen zur Einführung eines intelligenten Systems kennenlernen
Die Einführung einer solchen Software (teilweise in Verbindung mit generativer KI) ist nicht so komplex, wie es zunächst scheinen mag. Um ein besseres Gefühl für den Implementationsprozess bekommen, haben wir einen Blogartikel zum Thema Einführung einer generativen KI geschrieben. Auf unserer Webseite unter “Ressourcen” haben wir zusätzlich ein White Paper zu diesem Thema hochgeladen.
Weiterentwicklung der intelligenten Suche bei amberSearch
Mit amberSearch als Basis haben wir unseren systemübergreifenden Copiloten amberAI entwickelt. Damit bieten wir unseren Kunden einen Copiloten, der nicht ausschließlich auf ein Software-Ökosystem fokussiert ist, sondern wirklich systemübergreifend funktioniert:
In den nächsten Monaten und Jahren werden hier darauf aufbauend noch einige weitere spannende Funktionen folgen.
Weitere Anmerkungen
Der Anspruch dieses Blogartikels ist es, die grundlegenden Funktionsweisen verschiedener Suchtechnologien zu erklären sowie die Vor- und Nachteile aufzuzählen. Zusätzlich möchten wir einen ersten Eindruck der technisch vorhandenen Grenzen geben. Unterschiedliche Anbieter entwickeln, basierend auf diesen Ansätzen, ihre Systeme unterschiedlich weiter. Ein großer Punkt ist bspw. die Berücksichtigung von Zugriffsrechten. Es gibt Anbieter, die ausschließlich für alle Mitarbeiter vorhandene Informationen durchsuchen, da Zugriffsrechte über deren Architektur nicht abbildbar sind. Bei amberSearch haben wir uns im Gegensatz dazu entschieden, die Zugriffsrechte über den Single-Sign-On (SSO) bzw. das Active Directory zu steuern, um IT-Administratoren die Nutzerverwaltung möglichst einfach zu machen und zeitgleich eine wirklich umfängliche Suchmaschine anbieten zu können.
Eine weitere Möglichkeit, um internes Know-How für Mitarbeiter zugänglich zu mache, auf die in diesem Blogartikel weniger eingegangen wurde, ist das Training eines eigenen KI-Modells. Da wir hier jedoch bereits einige Blogartikel [Sollte man Large Language Models mit eigenen Daten trainieren?, Was ist Retrieval Augmented Generation?] auf unserer Webseite haben, sind wir in diesem Artikel nicht tiefer auf dieses Thema eingegangen.