
In recent months, the term “Private AI” has become more and more important. But what exactly is private AI, why is it being talked about and is it really the optimal solution? In this article, we dive deep into the topic and shed light on the question of whether it makes sense to train Large Language Models (LLMs) with your own data.
Table of Contents
The current state of generative AI is one of progress and opportunity. Companies are faced with the challenge of how best to use the potential of these models, such as GPT-4, in combination with their internal know-how. Here, a central question emerges:
The challenge: Private or Public AI?
When companies decide to use AI models, they are faced with the choice of training them themselves with in-house data or relying on the services of large providers such as Google (Bard), OpenAI or Open Sourcemodels. The hurdles and concerns here are manifold and partly due to a lack of technical understanding. Let’s clear the air!
If you are considering using generative AI, you should read our blog article on the introduction of generative AI
What does Private AI mean?
Private AI describes the practice of training algorithms exclusively with data owned by an individual user or organisation. For example, when a machine learning system trains a model on a dataset of documents such as invoices or tax forms, that model remains solely for the internal purposes of the organisation.
The main advantage is that this avoids creating a common knowledge base from which potential competitors could also benefit.
And what is Public AI?
Public AI refers to AI algorithms that are trained on large amounts of publicly available data. This data usually comes from different users or customers. A well-known example is ChatGPT, which is based on information from the freely available internet such as text articles, images and videos. Public AI can also include algorithms that use data sets that are not specific to a particular user or company.
The illusion of one’s own: Training with your own data?
Many companies tend to take the supposedly safe route and want to train an AI model with their own data. They hope to share internal knowledge efficiently through a question-answer system. But there are various difficulties lurking here:
- Access rights: A trained model cannot take access rights into account, which can lead to inappropriate information pricing.
- Data selection: Selecting the right data for training is a complex task. Who makes this selection and how are access rights relevant?
- Costs: Training your own LLMs requires immense resources and know-how, which can quickly lead to high costs. Training an in-house AI model can quickly run into the high five or six figures when human capital and server resources are taken into account.
- Timeliness: In-house developed models are often outdated because they are not continuously updated. In addition, external AI models evolve rapidly. At today’s rate of development, publicly available models quickly beat self-trained models, which further argues against training one’s own AI model (see image 1). It is also important to consider whether the company is willing to provide the resources (server resources and human capital) in the long term to continue training its own AI model.
- Accuracy: Own AI models could generate incorrect or confusing information that is not verifiable due to a lack of references.
- Know-How: The necessary expertise for training is often lacking and can be expensive to acquire.
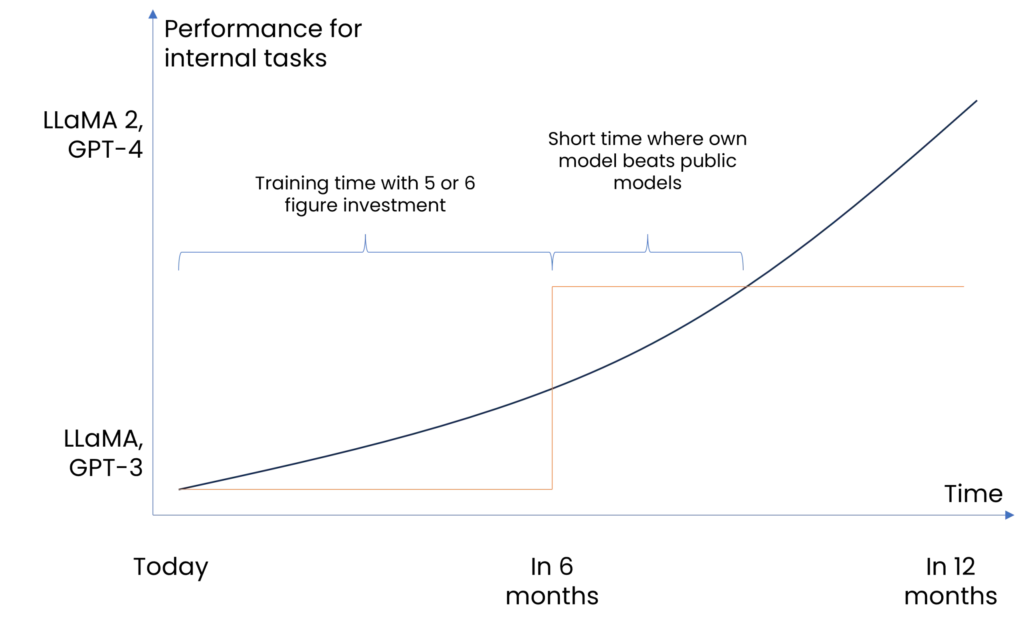
Image 1: Performance of private AI vs public AI
Basically, a model is only as good as its data. If only a data set is selected that is created from data that is accessible to all employees, then the response depth will not be particularly deep. On the one hand, this means that the system is not as strong as it could be and, on the other hand, employees use the system less or not at all. On the other hand, if “too much” data is used, then certain employees may receive information that was not actually intended for them (e.g. turnover with a customer, etc.).
A better solution to imitate a private AI: Enterprise search meets generative AI
Instead of falling into the pitfalls of one’s own training, a more effective alternative presents itself: Retrieval Augmented Generation. One can use the context that an enterprise search – in our case amberSearch – recognises to use it as the context for a generative AI model. The advantage is that the transfer of the context consumes virtually no computing time, which makes this set-up extremely powerful.
From a technical point of view, the enterprise search would pick out all relevant information, taking into account topicality and access rights.
This is then passed to an AI model as a context:
Instead of having to provide an answer from its own knowledge (without taking access rights into account), the artificial intelligence of the generating model is used to generate the right information from a defined context (access rights are taken into account). This is exactly what we do with amberAI.
To achieve this effect, we rely on public AI – but in an open-source variant. The open source model we use was refined without customer data (!) so that it is perfectly adapted to our customers’ use cases. So we use AI models that are trained with public data, but apply them exclusively for internal use cases. In this way, our customers retain data sovereignty, but can use the broad knowledge of the public to exploit comparable effects as with private AI. After that, the only question is where such a solution should be hosted.
With this approach, we beat several challenges that arise when training our own AI model:
- Referencing: We can reference where we have found which information so the user can verify if the found information is correct
- Timeliness: AI-supported search always finds up-to-date information.
- Consideration of access rights: Access rights are maintained and respected.
- No training with own know-how: Companies do not have to create and train their own AI models.
- Cost-efficiency: The solution is cost-effective and efficient.
- No extra know-how needed: By using a GDPR-compliant solution like amberSearch you don’t have to worry about needing your own experts
In short, our alternative works through the interaction of amberSearch and an open-source AI model that we have fine-tuned and that has general intelligence. The search determines relevant information based on access rights and timeliness. The generative model uses context to provide accurate answers without needing to be trained itself.
And this is what a solution might look like:
In conclusion, the private AI route with its own training effort is often not the most efficient. The combination of enterprise search and generative AI models offers a better solution. Companies should not fall into the trap of putting unnecessarily large amounts of data into their own models when an intelligent combination can deliver the desired output and, by training their own AI models, benefit one group of companies above all: Cloud providers.