Retrieval Augmented Generation is a powerful new NLP technique for enterprise search applications that solves many of the challenges that classic generative large language models (LLMs) have.
Table of Contents
Companies sense that generative AI is not building hype, but that generative AI will have a lasting impact on the business world. After the idea of training their own AI model initially existed in many companies, it was quickly discarded. The effort and disadvantages are simply too great: AI models are currently outdated too quickly and access rights are not taken into account. This makes them unusable for internal company use cases, where access rights and also the topicality of the information are a must-have. Read more in this blog article.
Retrieval Augmented Generation is a natural language processing (NLP) approach that combines the power of large language models (LLM’s) with the precision of information retrieval systems (enterprise search). Currently, many providers are rushing into the topic, as it is currently experiencing an extreme boom. Setting up such a system requires a lot of know-how, which we have successfully built up over the last few years. In addition to the connections to the company’s systems (e.g. SharePoint, drives, etc. – see Integrations), access rights, content relevance and up-to-dateness must also be taken into account in order to achieve good results.
In the following, we therefore explain the technical differences between a retrieval augmented generation-based system and a classical generative large language model.
Simple Large Language Model retrieval systems
In a classical Large Language Model, a question is posed to the generative AI model, which attempts to answer this question using the knowledge from the training dataset with which it has been trained. This training data set is rigid and has a cut-off date (in ChatGPT, for example, this was September 2021 for a long time, but is now January 2022). However, this only works if the model is re-trained, i.e. new resources are invested to keep it up-to-date (see first linked blog article).

Example answer of a simple Large Language Model
In our example, the LLM gives a perfectly legitimate and understandable answer, but it is based on the knowledge that was available up to the cut off date. Additionally, unfortunately, it does not reference where the answer came from.
Want to know how to successfully introduce generative AI into your company? Then read this blog post now!
What is the architecture for a classic LLM system?
In the following we have simplified the architecture of a classic LLM system:
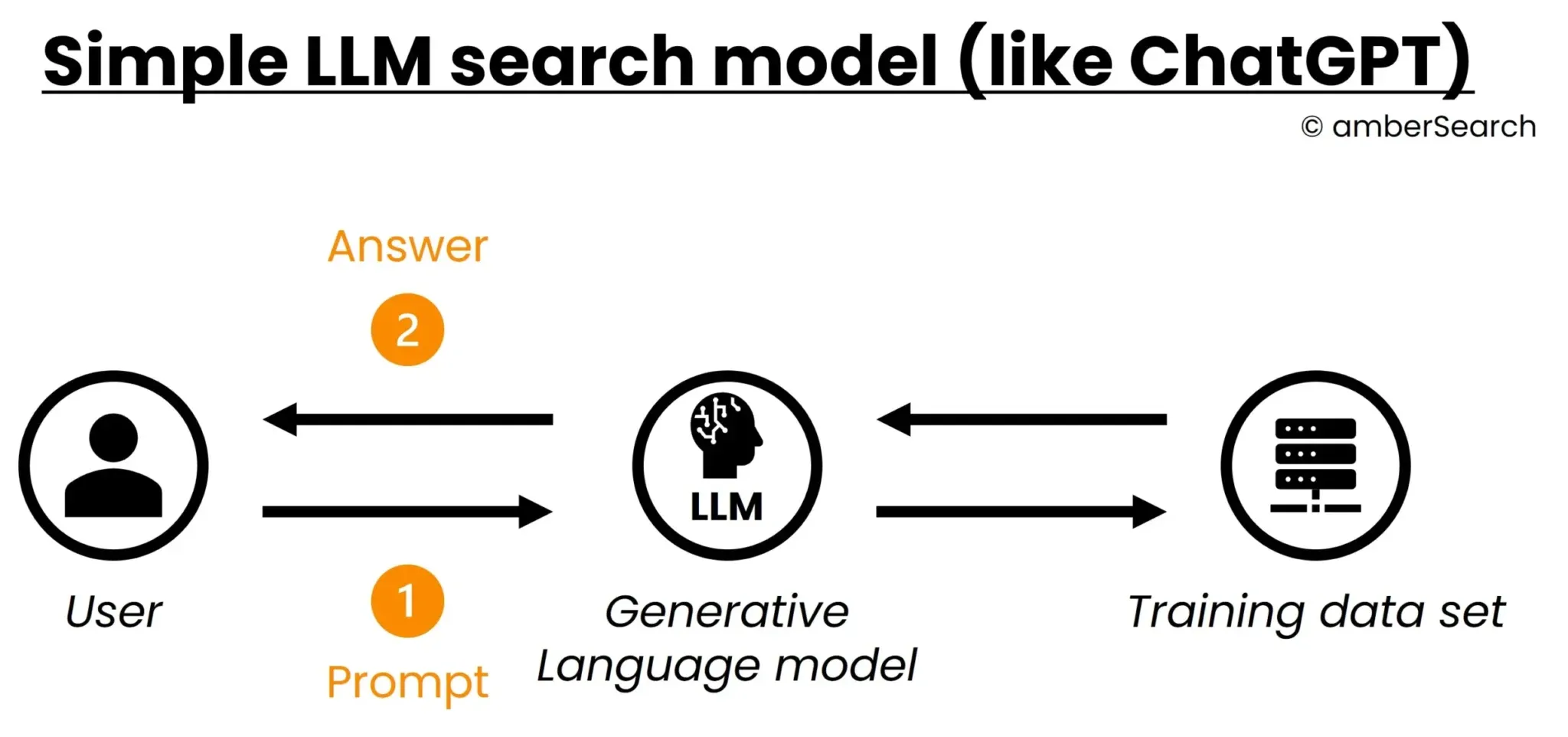
Simplified illustration of an LLM’s query process
In this case, the user asks a question to the generative language model [1]. This converts the question or prompt into a format that can be processed by the AI model and generates an answer based on this [2]. To generate this answer, the AI model uses the data set that was used for training.
The problem for both the user and the developer with classical LLM’s is that it is not logically comprehensible why a generative AI model formulates an answer – it is therefore a black box. For users this means:
- Classical LLM’s have no sources for their answers, but are only able to reproduce knowledge that you have “picked up” via the training dataset.
- Classical LLMs start to combine knowledge, which for us is like hallucinating and therefore not reliable.
- Classic LLM’s cannot answer questions with knowledge outside of their training data, but only questions with the information contained in your training dataset.
- Because the training dataset has no structure, access rights or the timeliness of information cannot be taken into account
In other words, LLMs are powerful tools, but they are not perfect. They can only answer questions based on the information they have been trained on, and they are not always accurate. When using LLM’s, users should be aware of these limitations. However, in corporate use, the aforementioned weaknesses are so severe that they make large-scale internal use of generative AI models unsustainable in most use cases.
Retrieval Augmented Generation System
In a retrieval augmented generation system, the answer would be formulated as follows:
Screenshot from our software amber. The orange part is the generated answer.
To counteract the weaknesses of LLMs mentioned above, we use a different technique with amber – namely Retrieval Augmented Generation.
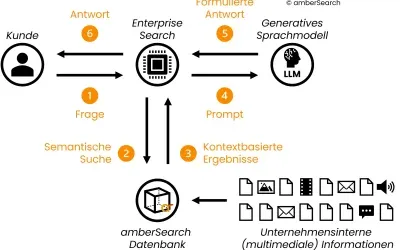
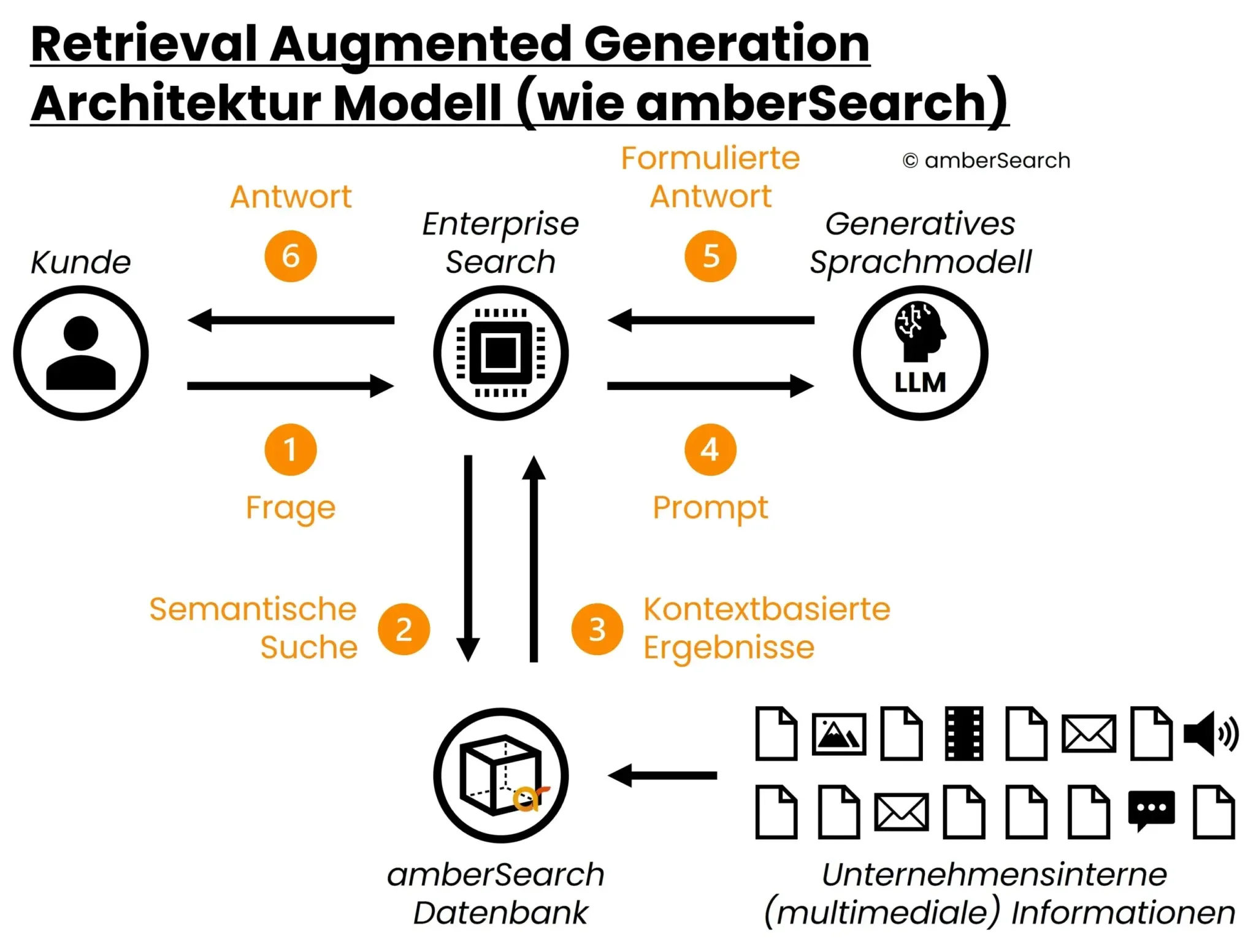
In such a system, before resorting to the generative AI model, a pre-filtering is done first, which ensures that answers are generated only on relevant, current and accessible information. For the pre-filtering we use our enterprise search – amber. This allows us to connect various internal systems (intranets, DMS, M365, Atlassian, etc) while taking access rights into account.With amberAI we then use the results found by amber to generate an answer matching the user’s question.So the architecture of the model looks like this:
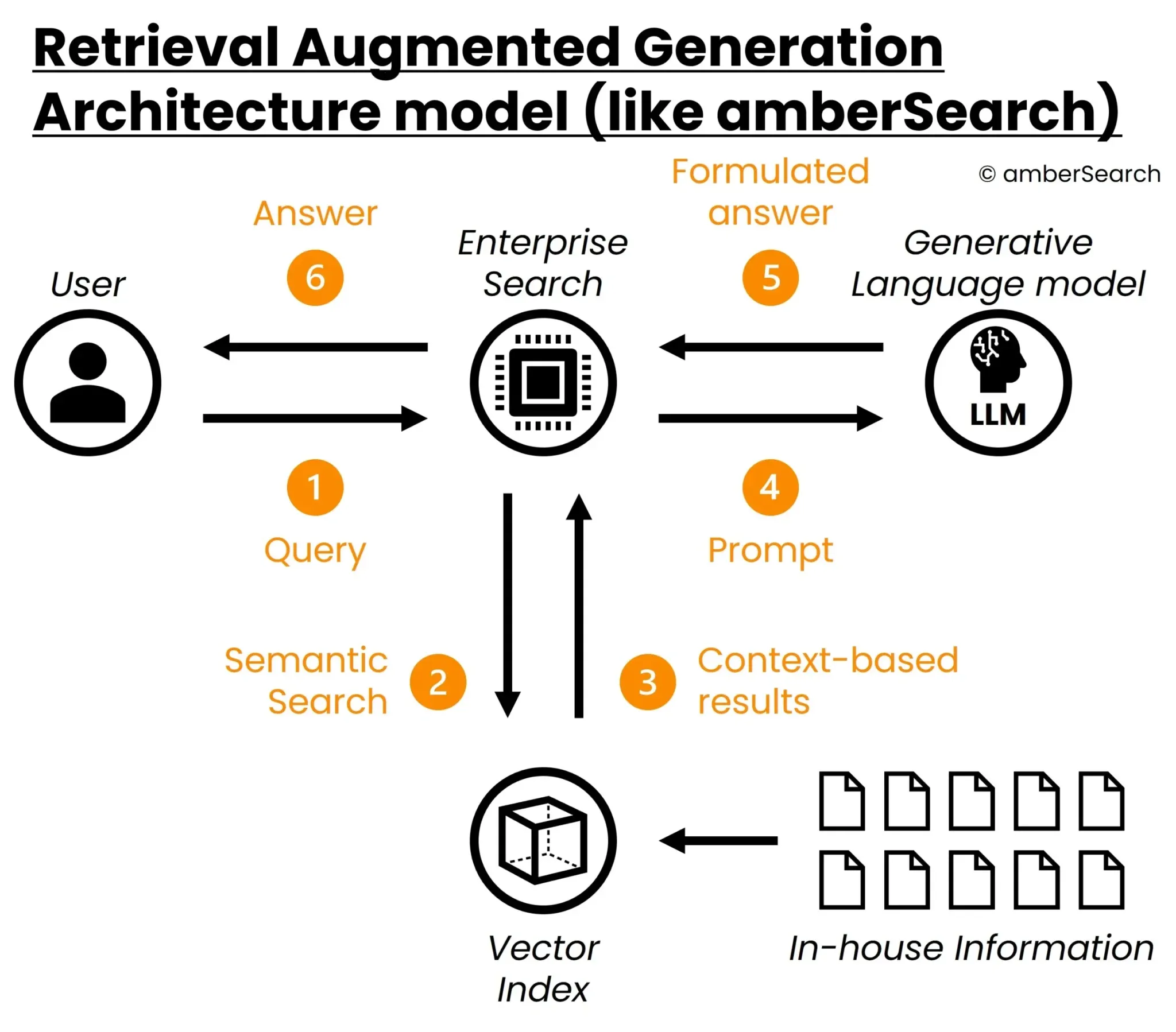
Representation of the architecture of a retrieval augmented generation system
First, the user enters a question into amber [1]. amber searches [2] – taking into account access rights – for the most relevant answers in an index containing the internal company content to be searched. This index is constantly updated so that users always have access to the most current information.These results are then passed by amber to a generative AI model in a prompt consisting of the found content and the query [3] [4]. Based on the given context, the AI model formulates an answer [5], which is then played out to the user via Enterprise Search [6].
Broken down, we have 2 processes. The process to search for an answer and a process to generate an answer based on it.
In order to successfully solve the first step, we have trained our own AI model, which we made open-source as early as 2020 (!). This has now received over 200,000 downloads and has been rated in several independent studies as one of the strongest available German-language models on the market (source 1-5). Internally, we are now several iterations further along that we have not open-sourced. Our amber database serves as the basis for this. This is a vector-based database in which we can store information from documents, images, videos and other multimedia content. Again, we are the only provider known to us who can offer such functions in this way.
Fun Fact: Large Language models as we know them today were first introduced by Google in 2017 at the Neural Information Processing Systems conference in Los Angeles. At amber, we were one of the first companies in Germany to recognise the potential and train one of the first German-language language models. Thus, there is hardly a company in Germany that has longer experience in the area of large language models than we do.
For the second step (amberAI) we also use our own AI model, which we have adapted to the needs of our customers. Further information on our development principles for amberAI can be found on our support page.
The next expansion stage for Retrieval Augmented Generation is Multi-Hop Q&A.
So what differentiates the two approaches and makes the Retrieval Augmented Generation approach a much more sustainable approach?
In the following table we have presented the most important differences between a simple large language model and a retrieval augmented generation system.
| Retrieval Augmented Generation | Classic Large Language Modell |
| No hallucinations: Because retrieval augmented generation systems rely on a given context, the risk of hallucinations is significantly lower. | Generating a response based on knowledge of large language models means that different information is mixed, leading to hallucinations. |
| Referencing: With this context-based approach, we are able to reference the origin of information so that users and developers can understand how answers come about. | By relying on knowledge coming from the AI model itself, it is not possible to understand why a particular answer is generated. |
| Training of AI models: With this approach, AI models do not need to be re-trained on customer datasets. Only the general intelligence of these models is used to understand what the documents are about in order to evaluate them or provide answers. | If the AI models are not trained with a good training data set, the results will not be good. In addition, the model is outdated again almost as soon as it goes live (due to training time). Resources must be kept constantly available to retrain the AI model. |
| Interchangeability of AI models: Currently, new AI models and further optimisations are published almost daily, which overtake any individual training (also taking into account the necessary resources) within a very short time. With an architecture in which AI models do not have to be trained customer-specifically, AI models can be exchanged much more quickly and are thus much easier to keep up to date than individualised systems. | In order to be able to use newer AI models, resources have to be spent again on training or selecting the data set, implementation, etc. The newer AI models can be used in the same way. |
| Access rights, timeliness & relevance: By using an intelligent search like amber, it is ensured that a user only finds the information to which he really has access. In addition, amber is able to incorporate relevance and timeliness into the evaluation of the results, which further improves the quality of the results. | Because answers are generated from the knowledge of the AI model, it is not able to take into account information such as topicality, relevance or access rights. |
| Rigid vs. flexible data set: Using the retrieval augmented generation approach, individual content can also be used from mails, team messages or other restricted content in compliance with the GDPR. This means that a system can be used for a wide range of applications, for example in customer service, sales or development. | Because a classical large language model is based on a rigid training data set, a new data set must be defined and a new AI model trained for each use case. This costs an incredible amount of resources and prevents the sustainable use of generative AI in companies. |
| Security & privacy: The architecture of Retrieval Augmented Generation systems means that no AI model needs to be re-trained with customised information. This gives companies a much better overview of what is happening with their data. | In order to be able to train their own LLM, companies must release at least part of their know-how for the training of an AI model. This carries a certain risk that know-how will flow away. |
| Compensate for weaknesses: This approach combines several AI models with each other to compensate for the weaknesses of the different AI models | Is only based on an AI model and has no possibility to compensate for its own weaknesses (hallucination, timeliness, access rights, …) |
Contextual RAG – the next stage of development
Classic RAG, as described in this blog article, forms the basis for many AI platforms. However, the approach has now evolved significantly. Our blog article on contextual RAG explains exactly how.
What makes amber unique?
Setting up such a system is not easy and requires a lot of know-how. At amber, we offer both of these process steps (search and answer generation) from a single source, without being dependent on third-party providers. This gives us full ownership over our pipeline and allows us to make adjustments at any point. Other providers either don’t have the ability to combine their chat systems with internal data sources or have to rely on third-party providers like Google Bard, OpenAI or Aleph Alpha to offer generative AI. In addition, we can not only deal with textual information, but also with multimedia content – i.e. information stored in images, scanned documents, videos & co. Watch the video below to see what amberAI can look like or try our solution directly in our free online demo with a demo dataset of over 200,000 documents!
You want to learn more? Then send us a contact request here and we will get back to you as soon as possible:
Sources:
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9090691
- https://www.scitepress.org/Papers/2023/118572/118572.pdf
- https://www.researchgate.net/publication/365493391_Query-Based_Retrieval_of_German_Regulatory_Documents_for_Internal_Auditing_Purposes
- https://arxiv.org/pdf/2205.03685.pdf
- https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=3787&context=dissertations_2
- https://link.springer.com/article/10.1007/s10791-022-09406-x