
Few departments in companies are as knowledge-intensive as the R&D department. And unlike other departments, knowledge in R&D does not expire, but must be used again and again.
This is especially true for companies where know-how is the most important asset.
At the same time, R&D departments mostly have the same problems. They too are going through the digital transformation, have information stored on network drives, M365, the intranet or in the DMS and have to ensure that all colleagues always have access to the latest knowledge.
Now R&D departments are facing 2 big challenges:
- How to make decentralised knowledge accessible to all employees – preferably without introducing a new data silo?
- How can lessons be learned from past experiments, even if the information comes from different documents?
A lot has happened in these areas in recent months. On the one hand, software solutions are developing towards becoming more open and more interconnected via so-called interface access, on the other hand, the current developments in the field of AI enable completely different use cases.
How can data silos be broken up?
The problem with data silos is that employees – as soon as they are looking for information – are usually faced with the following questions:
- Where do I have to look?
- What do I have to look for?
- Who can I ask for help?
In most companies there are several logically correct filing locations. As a consequence, a lot of time is spent on internal research, asking around (and distracting colleagues from their work) and re-working information.
In the field of R&D, this often leads to the fact that lessons already learned on a topic are not taken into account and the same mistakes or experiments/sub-projects are made again.
By the way: In our blog article “Improve your workflows: 2 frameworks to capture the time spent on information research” – we present 2 methods how companies can find out how much time their team spends on researching information and how to calculate a business case based on this.
According to our clients, they invest between 25-30 minutes per employee per day to get the relevant information. This quickly translates into lost time per employee of almost 3 working weeks per year, which are only used for internal research.
What is the solution?
Due to the fact that IT landscapes are usually grown historically, they are very heterogeneous. And each solution often has its own justification for existence. The solution to this challenge is a higher-level layer that provides the employee with a central point from which he can search the different systems. This changes the workflow as follows:
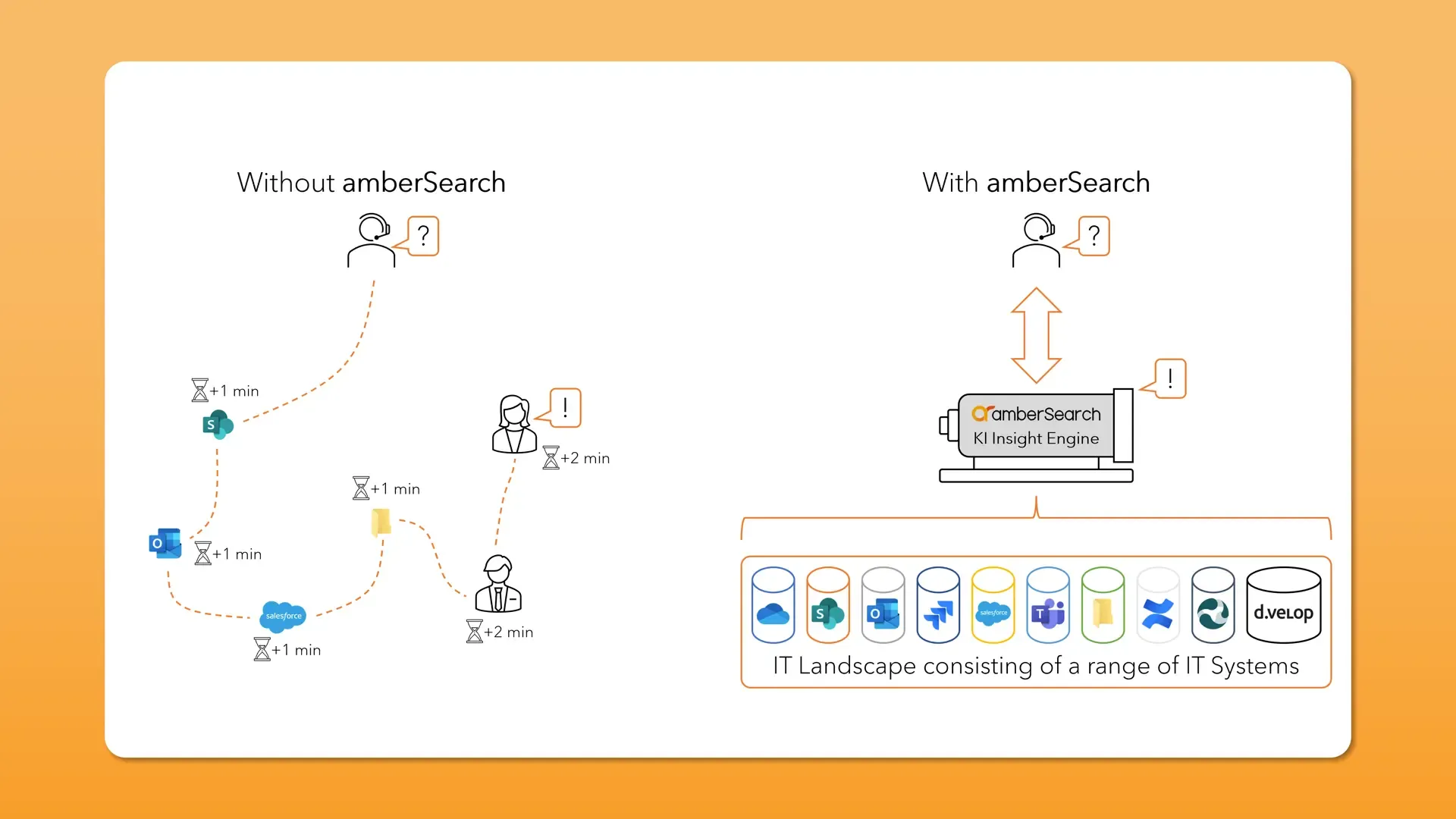
Process structure amberSearch Process level amberSearch The employee no longer has to rely on colleagues and the sometimes better, often worse search function of other systems when researching, but can search all systems with a cross-system search solution with a search syntax. This not only increases employee satisfaction, but also reduces search time by up to 40%.
By the way: We have developed an Excel tool to calculate the ROI specifically for your case. We have linked it here.
The advantage of amberSearch
amberSearch uses the latest developments in artificial intelligence to provide the employee in the company with the UX he knows from his private life. amberSearch is designed in such a way that it can also be used in companies with limited IT resources with very little effort. Our goal is to ensure that medium-sized companies can also benefit from the added value of modern technologies – of course taking into account the GDPR.
In addition, with amberSearch, text documents (including scanned documents), images, team messages, emails, 3D models, and all office files can be intelligently searched in full text.
How can artificial intelligence be used in the field of R&D?
Few technologies have been as present in the media in recent months as ChatGPT. However, ChatGPT only works with know-how from the internet.
amberSearch’s quality is already based to a large extent on artificial intelligence, including natural language processing and machine learning. In addition, we have developed a new function – amberGPT – and also use the technology that ChatGPT uses. This enables us – taking into account our customers’ internal know-how – to create answers with specific know-how. In addition, we can combine information from different documents.
Typical applications of amberGPT include summarizing projects, finding the results of specific experiments, or obtaining information on specific standards.
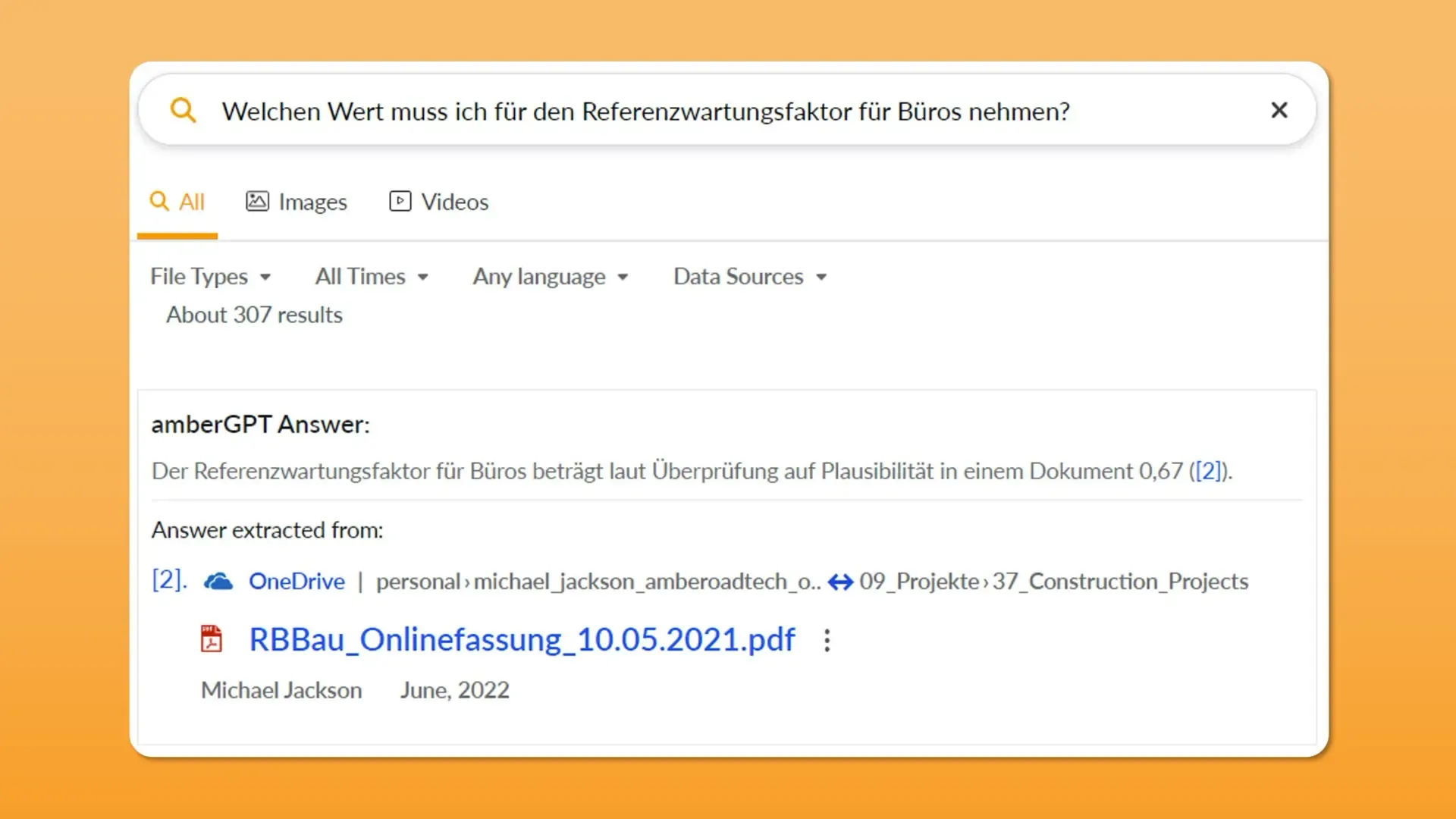
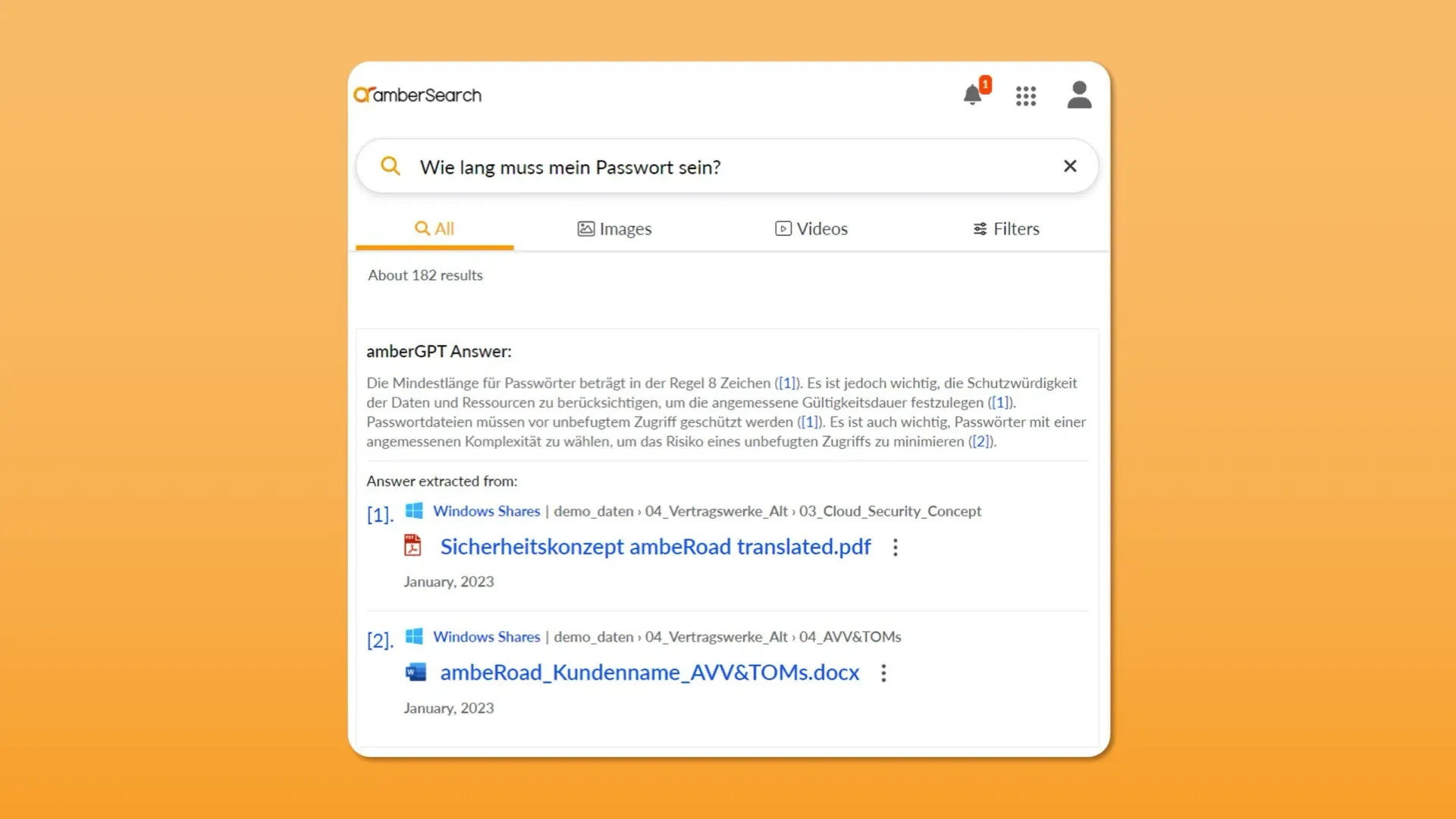
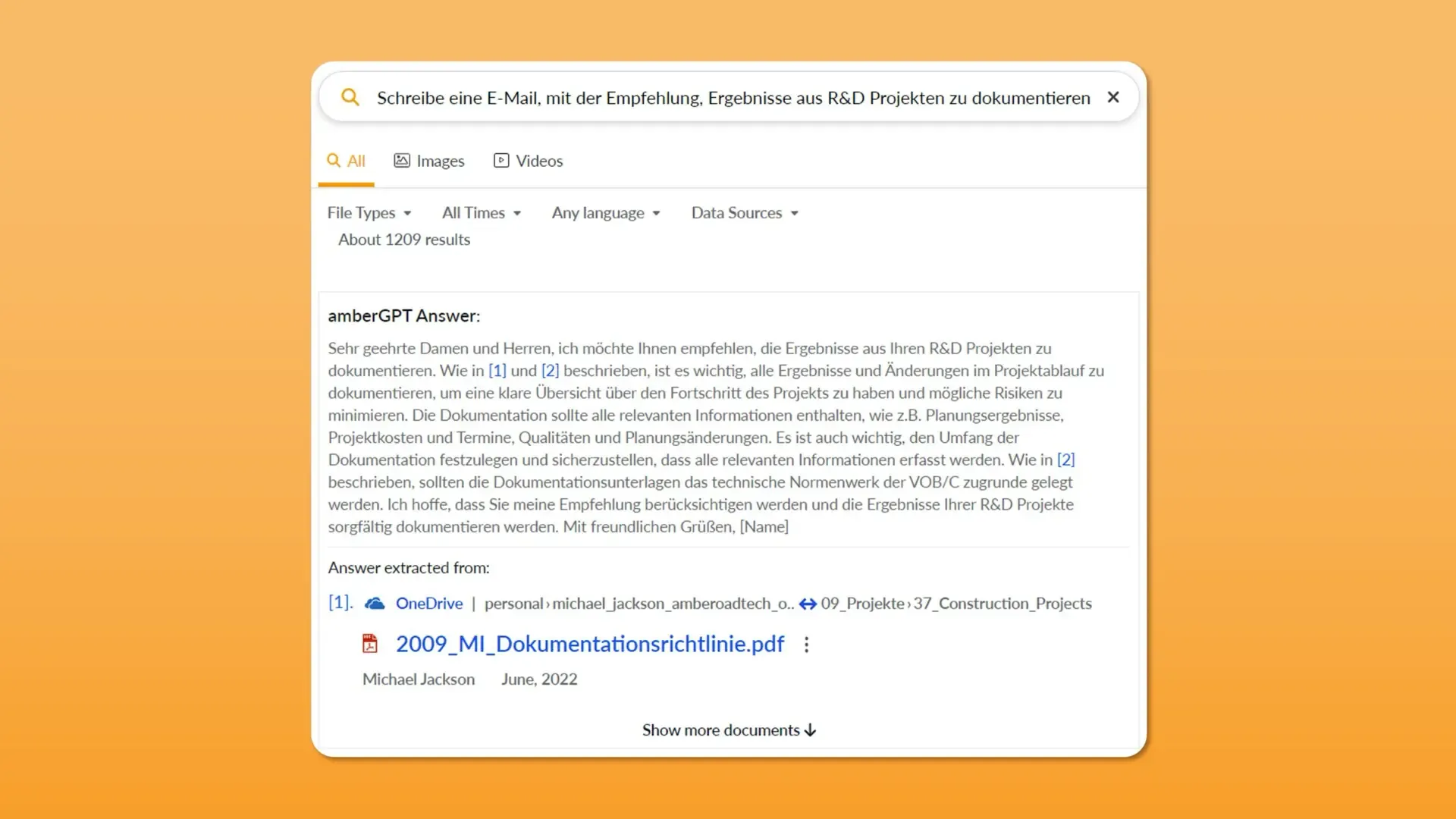
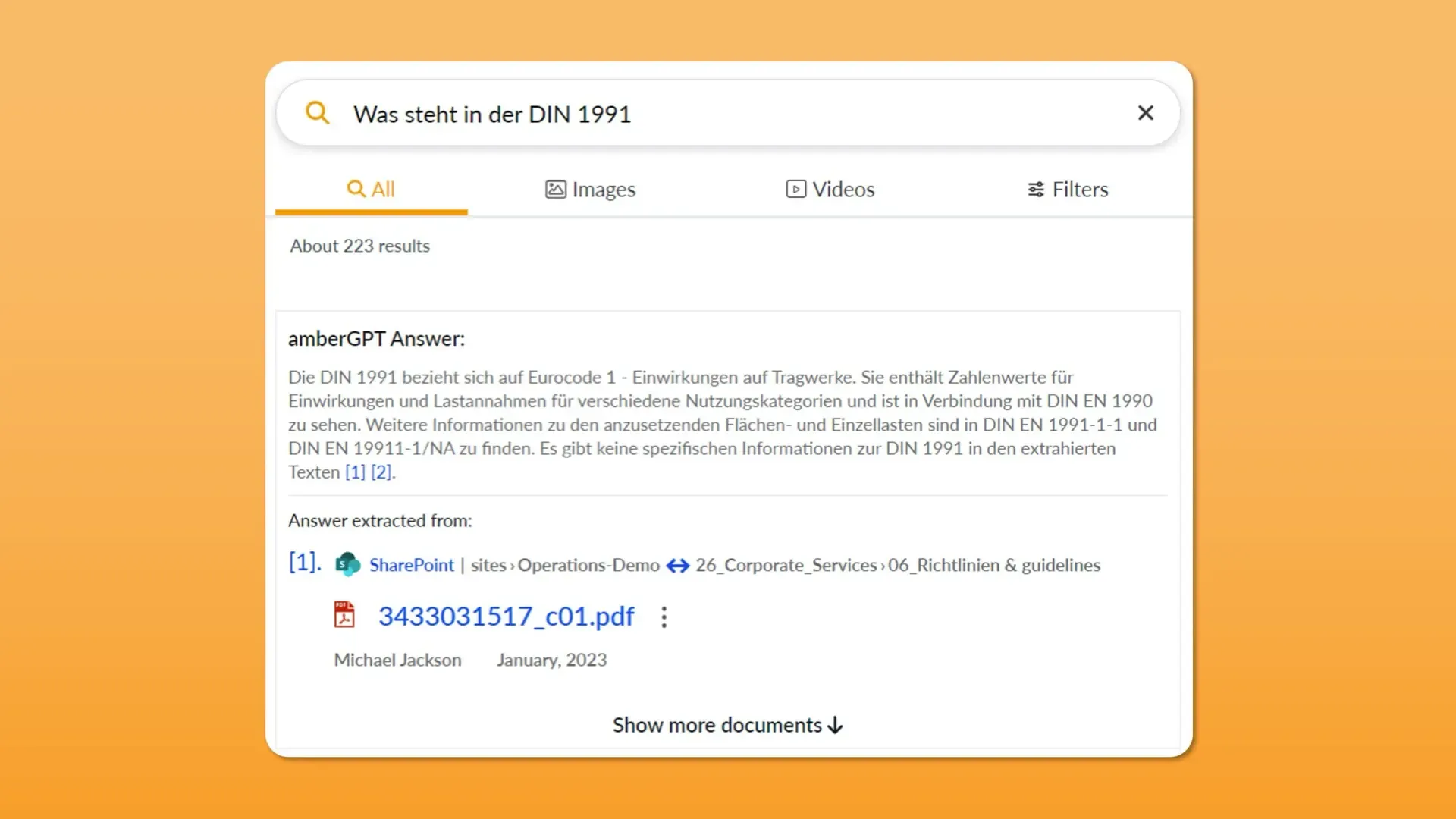
By the way: If you would like to try amberSearch, you can access it for free via this link!
Conclusion
Today, frustration, waste of time, or even the reworking of information no longer have to be with a smart, cross-system information management solution. With amberSearch, there is a provider who offers a tailor-made solution for medium-sized companies to quickly and efficiently access internal information.