
In den meisten Unternehmen liegt wertvolles Wissen nicht nur in Sharepoint-Ordnern, Laufwerken oder E-Mail-Postfächern, sondern auch in SQL-Datenbanken. CRM-Systeme, ERP-Module, Support-Tools, Produktanalysen: Jeden Tag entstehen dort Millionen Zeilen, die theoretisch alle Antworten enthalten und die das Management benötigt, um Entscheidungen zu treffen. Praktisch aber bleibt der Zugang zu diesen Daten ein Flaschenhals: BI-Teams sind überlastet, Reports sind veraltet, bevor sie verteilt werden, und Fachabteilungen warten Tage auf eine einfache Auswertung.
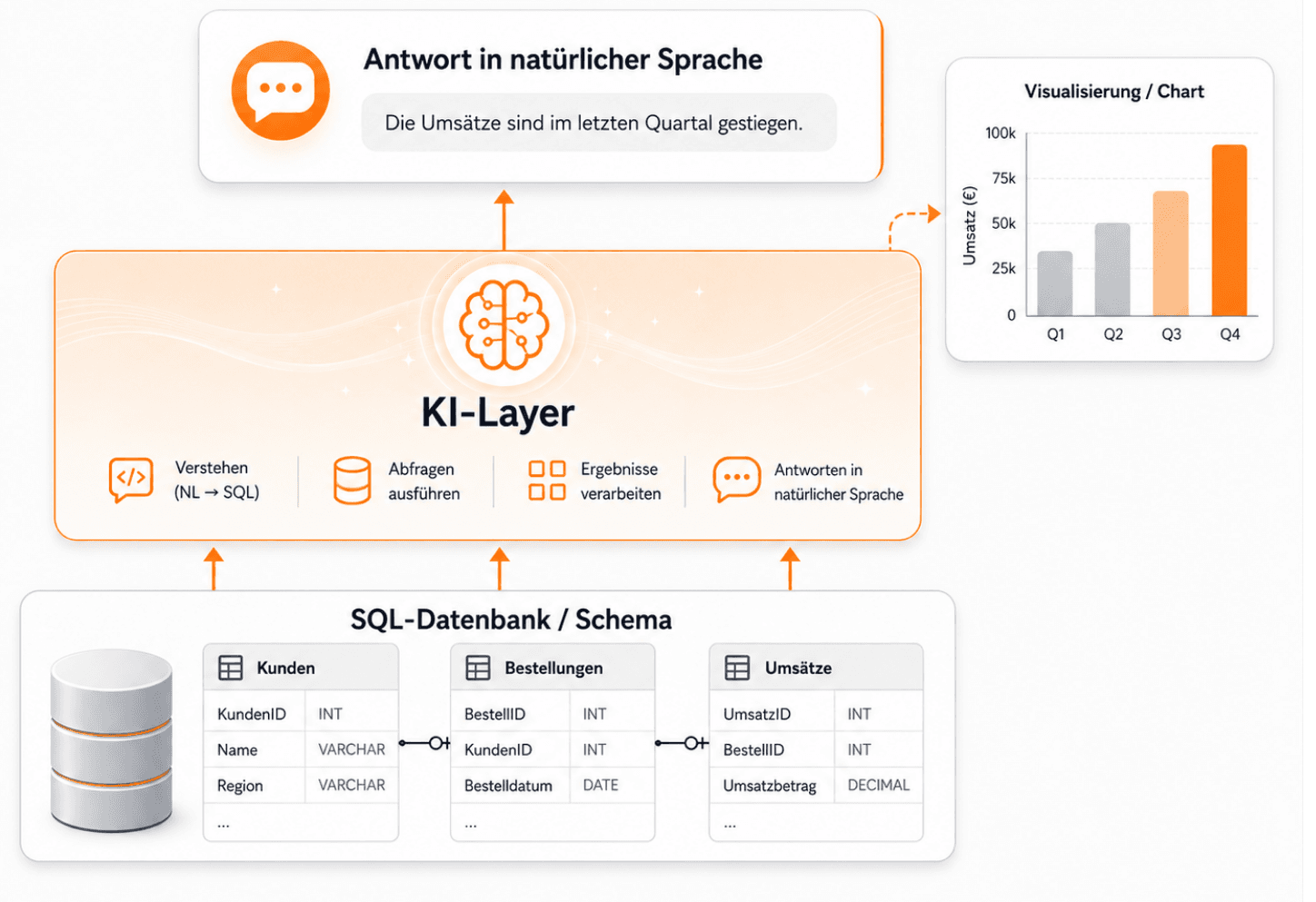
Genau hier verändert KI gerade die Spielregeln. Wer SQL-Datenbanken mit einer KI-Plattform anbindet, gibt jeder Person im Unternehmen die Möglichkeit, in natürlicher Sprache mit den eigenen Daten zu sprechen – und das Ergebnis als Diagramm, Tabelle oder PowerPoint-Folie zurückzubekommen. Das beeinflusst die Geschwindigkeit, Entscheidungsqualität und Datenkultur im Unternehmen massiv. Hier findest du einen vollständigen Überblick aller Integrationen.
Warum jetzt: Mit KI zur datengetriebenen Organisation
Datenbanken enthalten viele wertvolle Informationen, welche nicht mit Informationen aus Dokumenten zu vergleichen sind. Häufig sitzen auf diesen Datenbanken Business-Intelligence-Tools, welche einen guten Job für statische und wiederkehrende Dashboards gemacht haben. Aber sie sind nicht gut, um „mal eben“ eine Anfrage abzusetzen. Bei der Menge an Nutzern, welche Zugriff auf interne Daten benötigen, sind solche Tools heutzutage einfach zu langsam. Jede neue Sicht braucht ein neues Dashboard, jede neue Kennzahl ein Ticket. Text-to-SQL auf Basis großer Sprachmodelle verändert diese Logik: Statt Anfragen zu sammeln und zu priorisieren, generiert die KI die SQL-Abfrage in Sekunden – kontextbewusst, schema-treu und nachvollziehbar.
Für Entscheider und Nutzer heißt das konkret:
- Spürbar weniger Ad-hoc-Anfragen an die BI-Abteilung – stattdessen Zeit fürs Wesentliche.
- Schnellere Entscheidungszyklen, weil Fachbereiche selbst explorieren und analysieren können.
- Bessere Datenqualität, weil Lücken und Inkonsistenzen sofort sichtbar werden, sobald Daten genutzt werden.
Wichtig dabei: Eine produktionsreife Lösung darf nicht nur „irgendein LLM gegen die Datenbank hängen". Sie braucht einen kontrollierten Zugriff (read-only), saubere Schema-Beschreibungen und auditierbare Abfragen. Genau so ist die SQL-Anbindung in amber gebaut.
So funktioniert's: SQL-Datenbank in wenigen Minuten an amber anbinden
Die technische Anbindung ist bewusst schlank gehalten – sie ist in unter fünf Minuten erledigt und kommt komplett ohne Code aus.
Schritt 1: Datenbank-Konnektor anlegen
In den Admin-Einstellungen unter „Konnektoren" findest du den Bereich Datenbanken. Über „Datenbank hinzufügen" legst du eine neue Datenbank an. Dabei werden verschiedene Datenbanktypen unterstützt wie beispielsweise Postgres, MariaDB, MySQL, Oracle DB oder MicrosoftSQL Datenbanken – inklusive vieler Managed-Services, die die entsprechenden Protokoll sprechen. amber stellt dabei stets eine sichere Verbindung zu den Daten sicher.
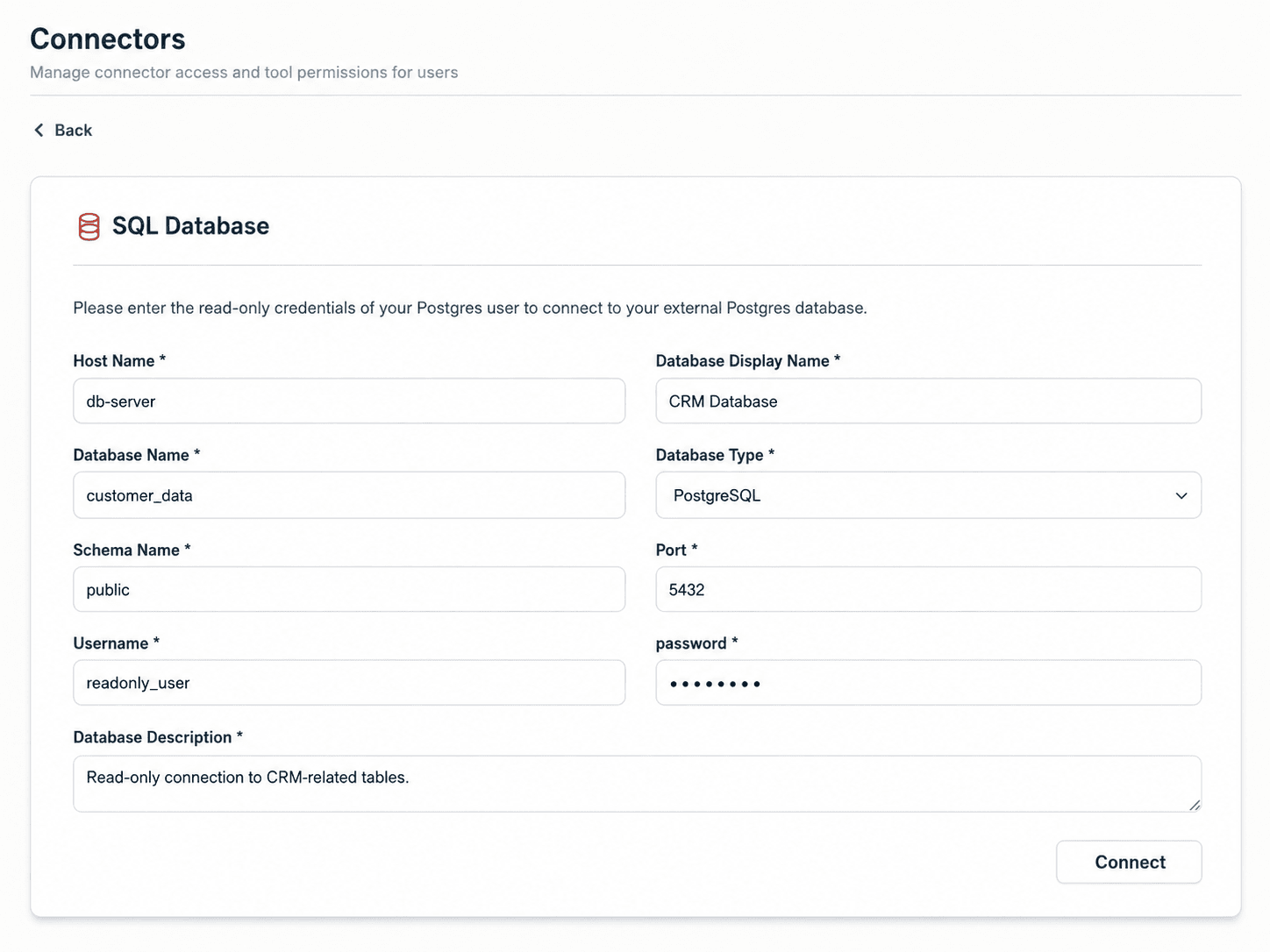
Schritt 2: Zugang konfigurieren
Im Formular hinterlegst du die typischen Werte: Host, Port, Datenbankname, Schema, Benutzer und Passwort. Bewusst nutzt du ausschließlich Read-only-Credentials – schreibende Zugriffe sind nicht vorgesehen. Hierfür empfehlen wir eher, einen MCP-Server auf die Datenbank zu setzen. Ergänzend kommt eine kurze Datenbankbeschreibung, die der KI später als relevanter Kontext dient („Das ist unser CRM mit allen Sales- und Support-Daten"), hinzu.
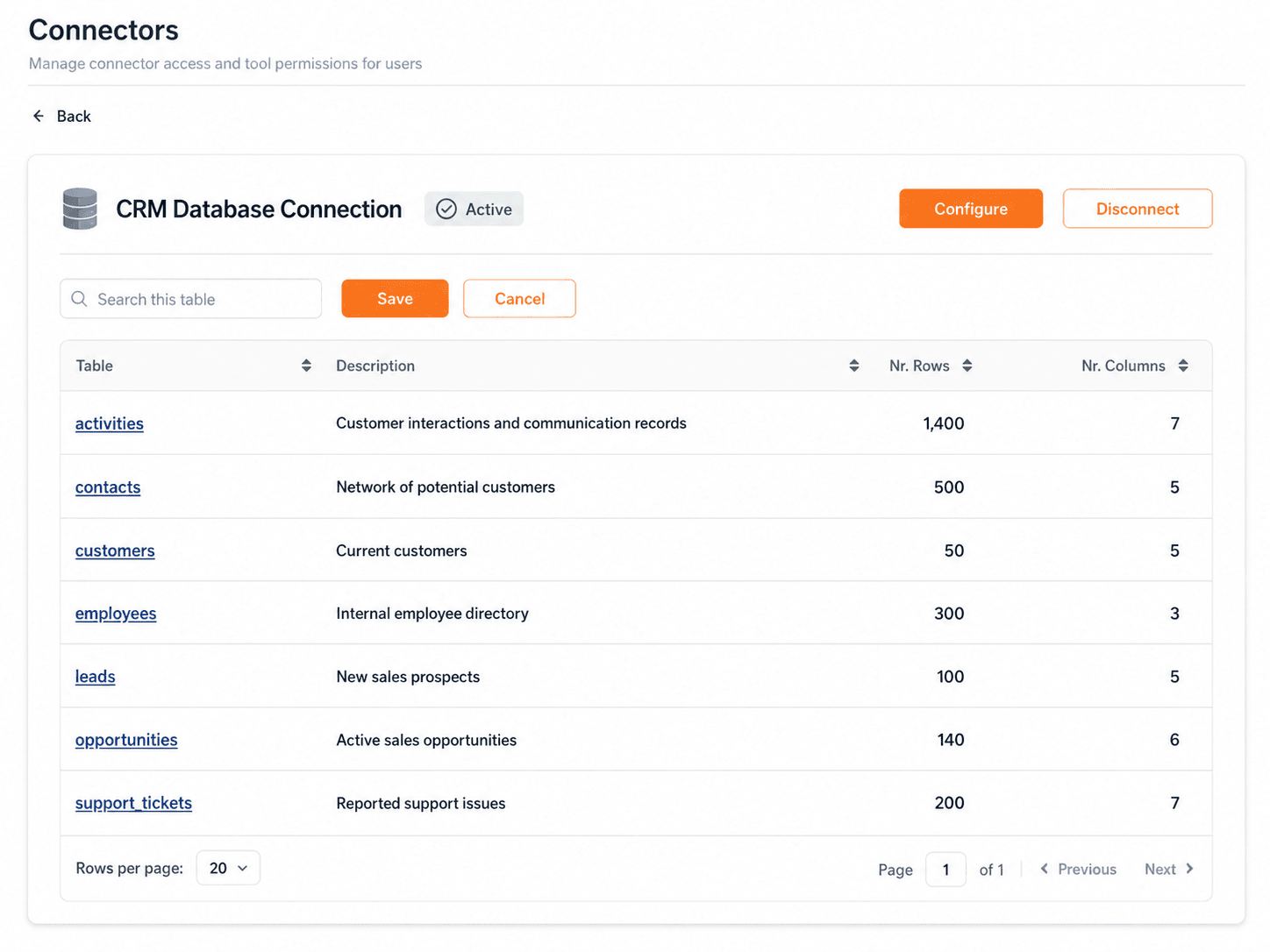
Schritt 3: Tabellen auswählen und beschreiben
Anschließend zeigt amber dir alle verfügbaren Tabellen im Schema an. Jetzt kuratierst du: Welche Tabellen soll die KI tatsächlich nutzen dürfen? Pro Tabelle hinterlegst du eine kurze Beschreibung in natürlicher Sprache – „Unsere aktuellen Kunden", „Alle Sales-Aktivitäten", „Reported Support Tickets" usw. Diese Beschreibungen sind entscheidend für die Trefferqualität, weil sie der KI das fachliche Verständnis geben, das in nackten Spaltennamen oft fehlt. Darüber versteht die KI, wann sie in welchen Tabellen suchen muss.
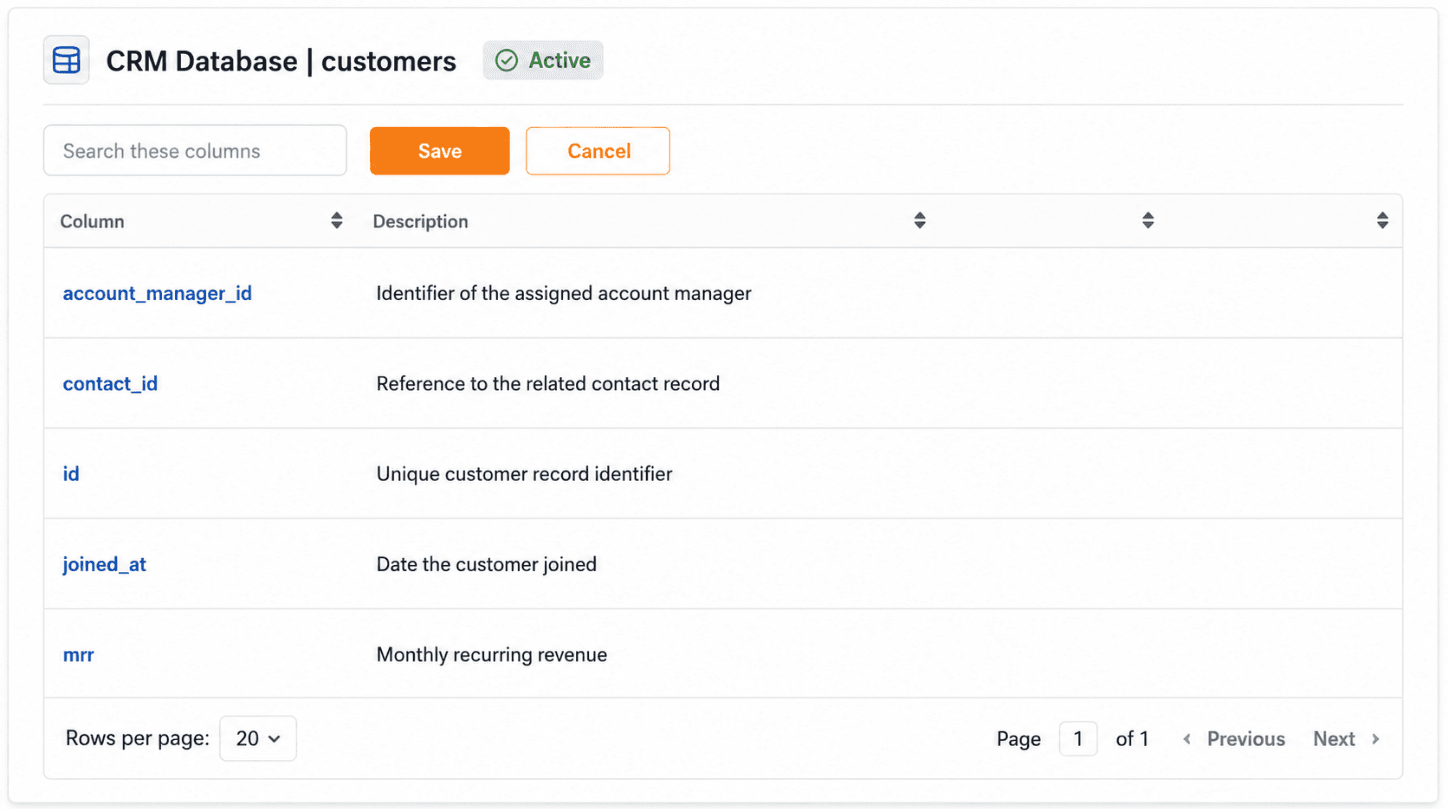
Schritt 4: Spalten verfeinern (optional)
Im nächsten Schritt kann man das Kontextverständnis noch weiter verbessern. Beschreibe einzelne Spalten – etwa „account_manager_id = ID des zuständigen Account Managers" oder „joined_at = Datum, an dem der Kunde Vertragspartner wurde". Diese Metadaten verbessern die Qualität der generierten Abfragen messbar, da häufig (gerade bei selbstdefinierten Spaltennamen der Sinn nicht eindeutig erkennbar ist).
Anschließend steht die Datenbank der KI ab sofort als Datenquelle zur Verfügung.
Drei Anwendungsfälle, die sofort Wert liefern
1. Datenbanken in natürlicher Sprache abfragen
Statt JOINs und WHERE-Klauseln genügt eine Frage: „Wie viele neue Leads hatten wir in Q1 pro Region?" oder „Welche zehn Kunden haben den höchsten MRR und wann sind sie eingestiegen?". Die KI übersetzt die Frage in eine SQL-Abfrage, führt sie gegen die angebundene Datenbank aus und liefert die Antwort – inklusive der zugrundeliegenden Query, sodass jede Auswertung nachvollziehbar und auditierbar bleibt.
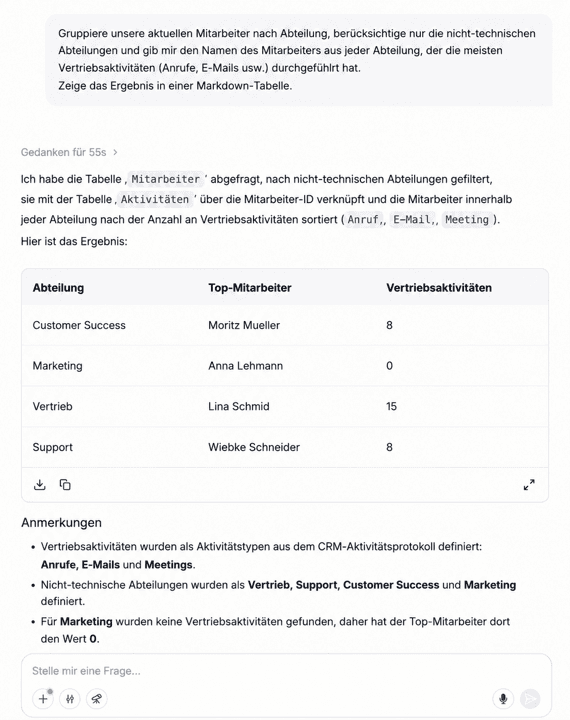
2. Aus Daten werden Diagramme – automatisch
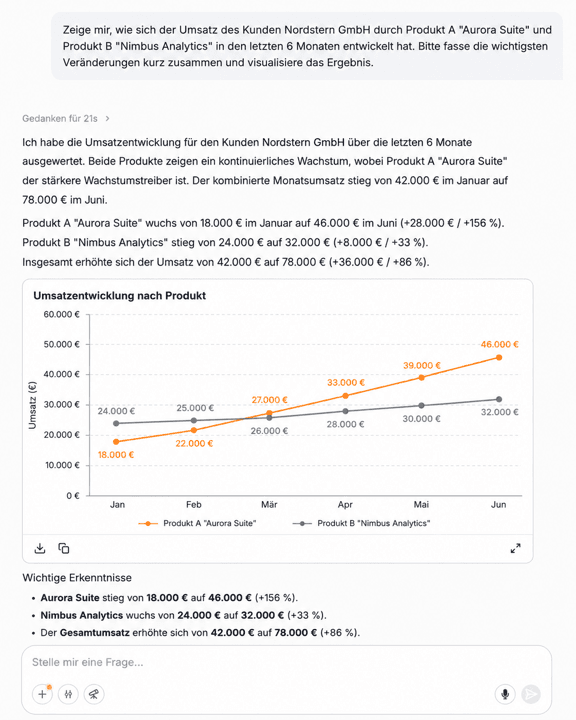
Auf dieselbe Antwort setzt du direkt auf: „Mach mir daraus ein Balkendiagramm nach Region" oder „Zeig die MRR-Entwicklung der letzten zwölf Monate als Liniendiagramm". amber generiert die Visualisierung on-the-fly. Statt drei Tools zu wechseln (SQL-Client, Excel, BI-Tool), passiert alles in einem Dialog. Das beschleunigt nicht nur den Analyse-Zyklus – es senkt auch die Hürde, überhaupt mit Daten zu arbeiten.
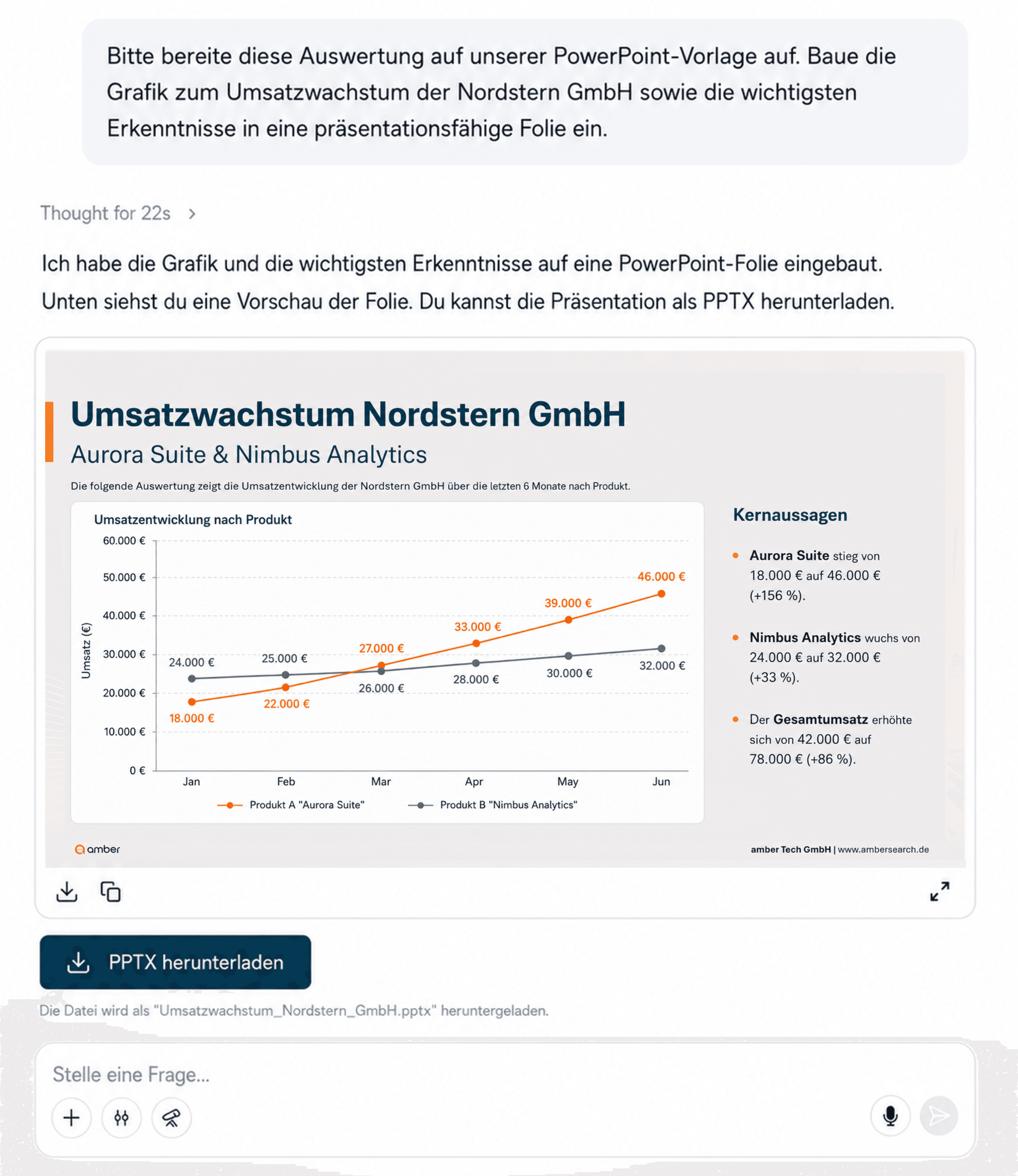
3. Direkt in deine PPTX – im Corporate Design
Der vielleicht größte Hebel für Management-Workflows: Generierte Diagramme lässt du direkt in deine eigene PowerPoint-Vorlage einbauen - inklusive Corporate-Design-konformer Farben, Schriften und Layouts. Statt am Freitagnachmittag Screenshots in Folien zu kleben, entsteht dein Steering-Deck in Minuten. Vorstandsmeetings, Investor Updates, Sales Reviews - jede wiederkehrende Folie wird zur datengetriebenen Routine.
Datenbank an KI anbinden: Die nächsten Schritte
Wenn Unternehmen strukturierte Daten einsetzen, dann sollten drei Fragen gestellt werden:
- Welche zwei, drei Datenbanken würden die meisten internen Fragen beantworten, wenn sie auf Knopfdruck zugänglich wären? Meist sind es CRM, ERP oder selbstentwickelte Systeme.
- Welche Zugriffsmodelle sind realistisch? Read-only-Credentials in einem isolierten Schema sind der pragmatische Startpunkt – ohne Risiko für produktive Daten.
- Welche Workflows würden sich am stärksten verändern, wenn Fachbereiche ihre Auswertungen selbst in natürlicher Sprache erstellen und als CI-konforme Folie exportieren könnten?
Die Anbindung selbst ist kein Großprojekt mehr. Der eigentliche Sprung ist organisatorisch: Daten werden vom Engpass zur Ressource, die jede Person nutzen kann.
Aktionen in Datenbanken mit KI ausführen
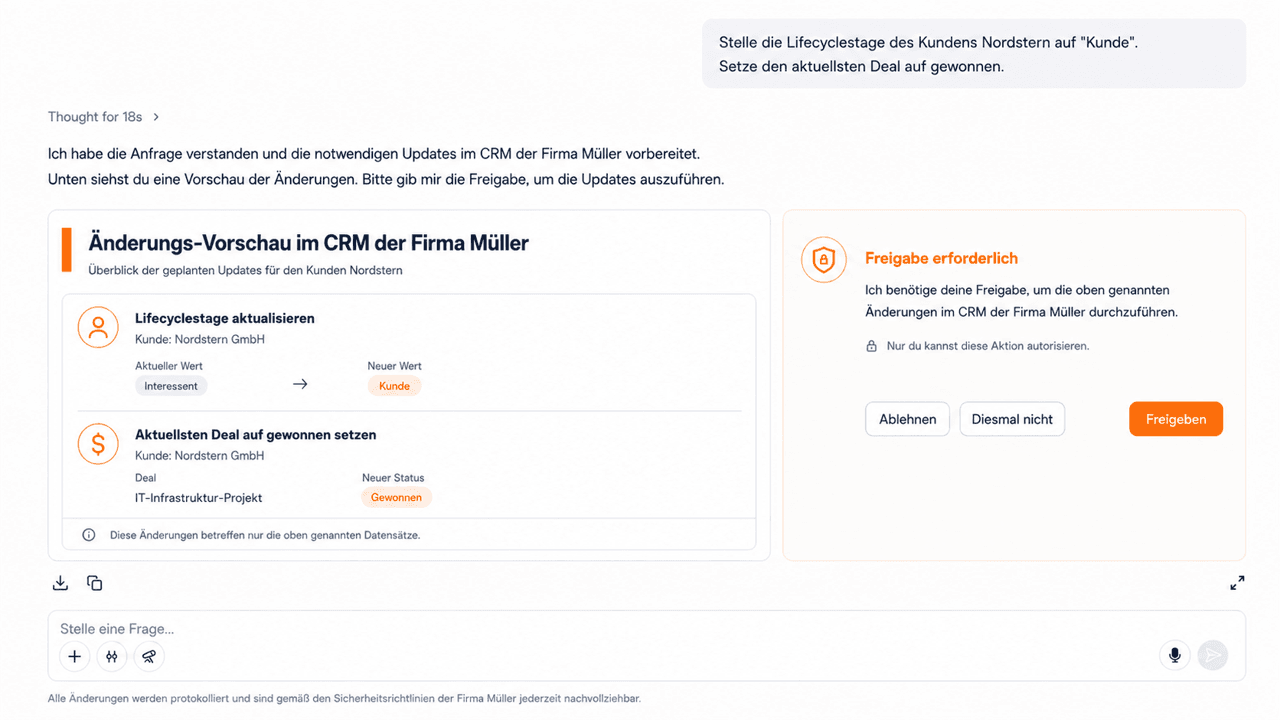
Ein weiterer großer Mehrwert, welcher durch Technologieentwicklungen seit 2025 möglich ist, ist die Fähigkeit für KI-Modelle Aktionen in Drittsystemen auszuführen. Technisch setzt man dabei auf die Schnittstelle des „Model Context Protokolls“ (s. MCP-Server).
Je nach Anbieter stellt entweder der Anbieter selbst einen MCP-Server zur Verfügung oder bei selbstentwickelten Lösungen kann man dem MCP-Server auch selbst entwickeln. Dieser kann dann von KI-Lösungen genutzt werden, um zum Beispiel eine Information in der Datenbank zu ändern. Beispiel: Ein Kunde kündigt per E-Mail, diese wird vom Supportmitarbeiter bestätigt. Die KI erkennt die Bestätigung und aktualisiert den Status des Kundens auf „gekündigt“. Im Gegensatz zu den restlichen, in diesem Absatz beschrieben Fähigkeiten handelt es sich bei diesem Ansatz natürlich nicht um einen Read-only Ansatz, sondern um eine schreibende Fähigkeit.
Du möchtest sehen, wie das mit deinen Daten aussieht? Vereinbare ein 30-minütiges Live-Demo-Gespräch und verbinde deine erste SQL-Datenbank gemeinsam mit unserem Team.