
Many companies are recognising the potential that generative AI offers them in combination with in-house expertise. However, for many companies, the best practices and functionalities are still completely unclear. This blog article helps interested companies to better understand the technology and processes.
Table of Contents
What use cases can be solved by combining internal company data with generative AI?
Imagine you have a kind of ChatGPT with in-house expertise. This results in various use cases. Some specific use cases are shown in the screenshot below:
Correct application of standards in product development
Few departments are as know-how intensive as product development. It is particularly important to be able to access internal know-how quickly. One use case, for example – as shown in the screenshot using the technical rules for drinking water installation – could be that employees are looking for a specific value to calculate:
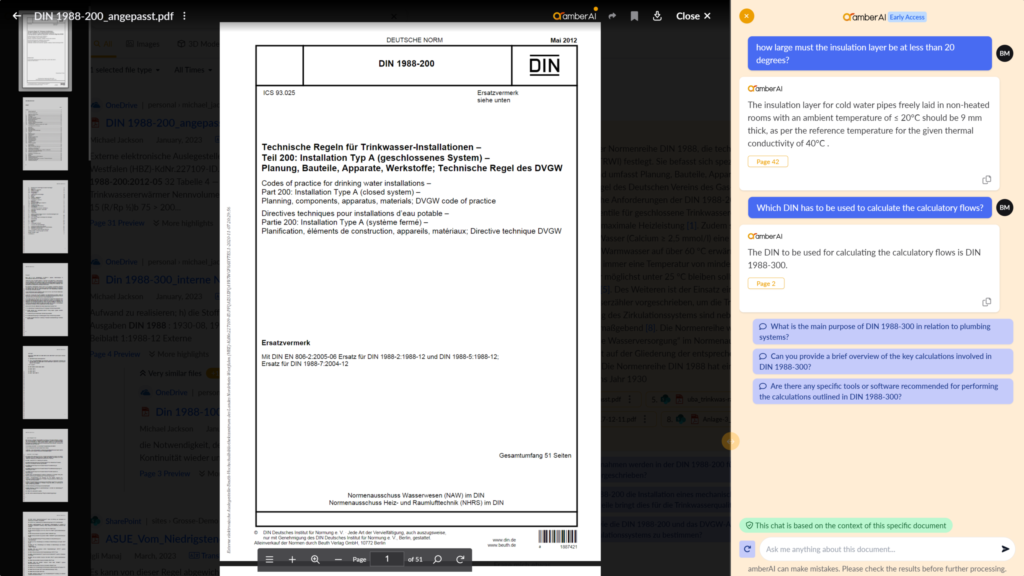
Figure 1: Screenshot from the amberSearch software showing the possible application of generative AI to internal company expertise
In this case, only the information from the standard is used to generate an answer to the employee’s question. So that the AI’s statement is not blindly trusted, a reference to page 42 has also been added so that employees can directly understand from which page the value was taken.
Finding decentralised information
For many use cases, the information is distributed across various systems. You therefore need information from drives, SharePoint and possibly a ticket tool such as Jira. If you combine an intelligent enterprise search with generative AI, you can combine the intelligent search with generative AI so that the generative AI summarises the information:
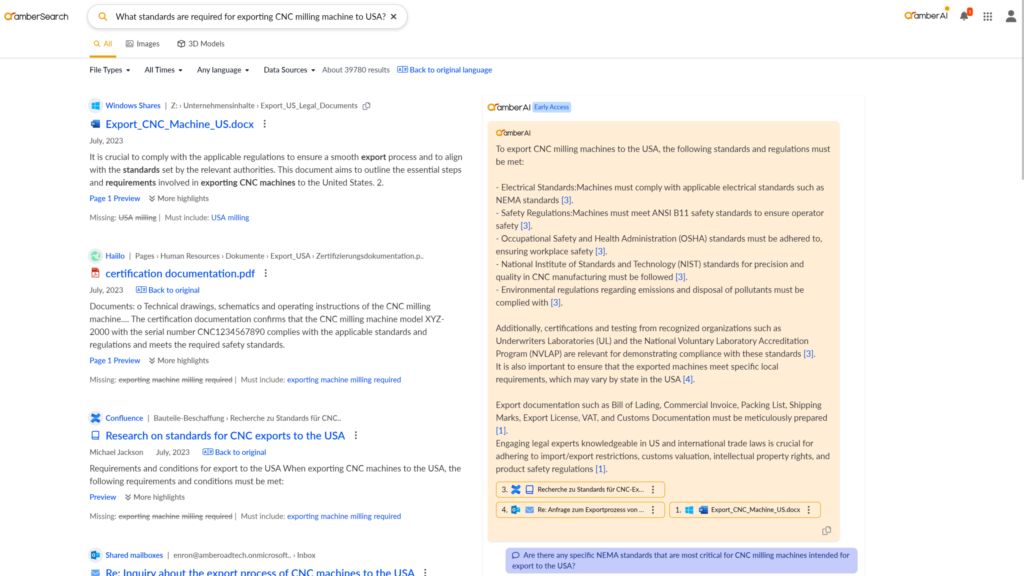
Figure 2: In order to answer a question, information from decentralised data silos often has to be taken into account. This screenshot shows how an LLM-based search can be used to find internal company information.
The screenshot clearly shows that a Google-like search is used on the left-hand side to find information from Confluence, Outlook and Teams, for example. On the right-hand side, the generative AI amberAI summarises the results found and refers to the various files that were found as part of the search process. Here, too, it is quickly apparent that all information has been well referenced and summarised in a comprehensible manner.
Summarise email histories with the help of generative AI
Employees often become part of a longer email history at some point. This gives employees the opportunity to read through all emails or to summarise the history with the help of generative AI or to ask again:
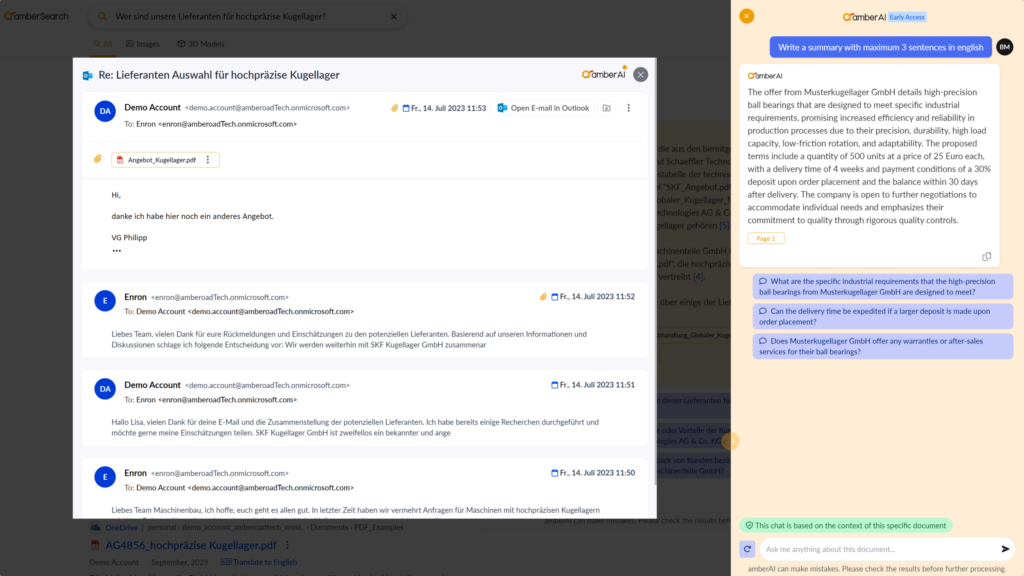
Figure 3: Summarising a longer email history
The screenshot shows how a summary was generated in this case based on an email history. This makes it much easier for employees to access internal company expertise.
Generative AI can reduce support requests
One of the first use cases mentioned in combination with generative AI is usually the use case of support. Support can be both external and internal. The screenshot shows an example of an internal support case:
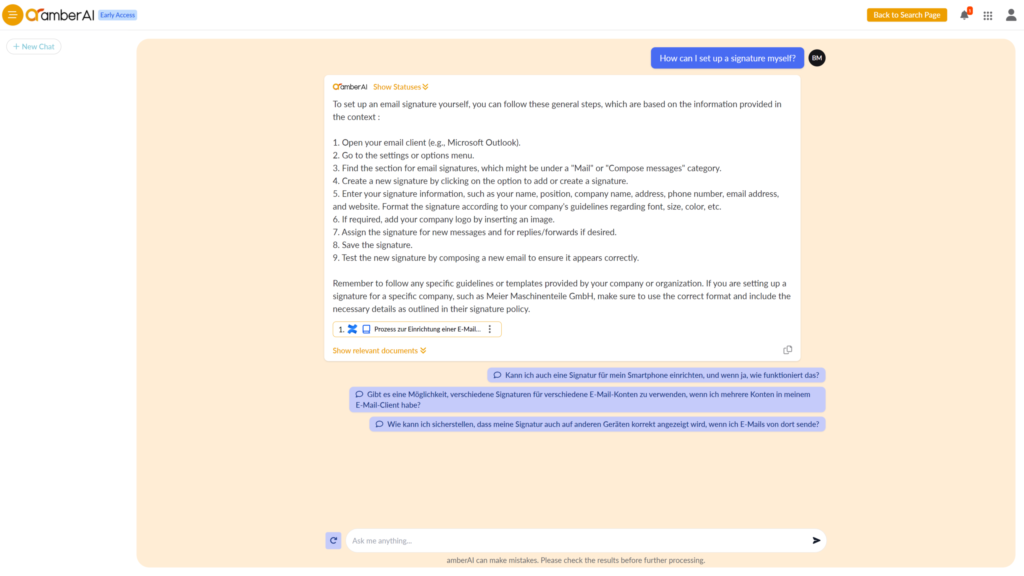
Figure 4: Example of answering a technical question in an internal support case
IT is often blocked with technical queries for which there are actually already answers in guidelines or support documents. Using a classic chat, employees can simply ask the AI the questions with the help of generative AI. The screenshot shows that detailed step-by-step instructions have been generated for the question: “How can I set up a signature myself?”. However, this answer does not come from the “intelligence” of the AI model itself, but from a confluence document that was referenced in a comprehensible way.
Searching for contact persons and generating an email
Generative AI can be used to formulate emails with the company’s details. An example is shown in the screenshot:
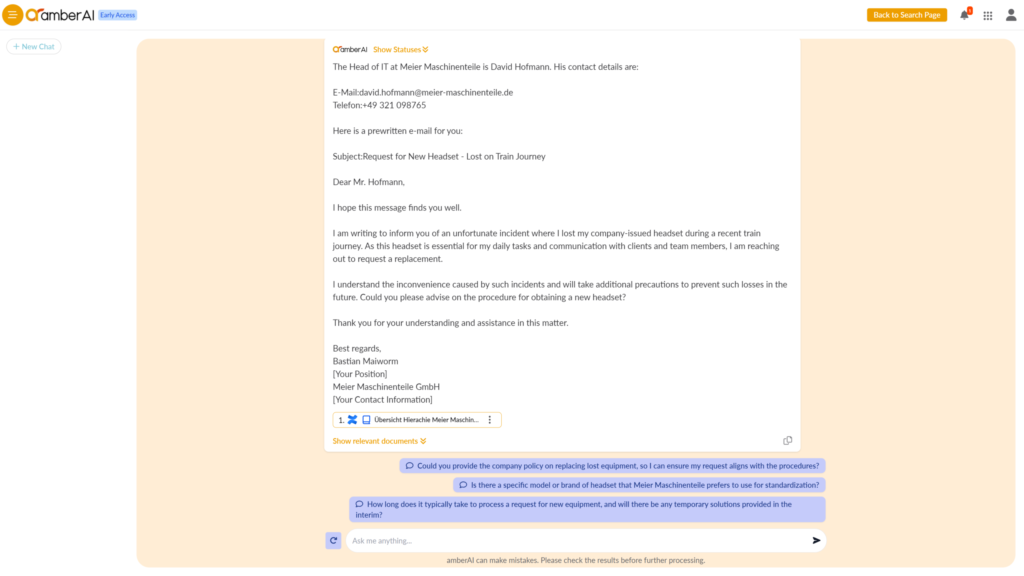
Figure 5: Description of an example of generating an email that incorporates internal expertise
Of course, any online tool can pre-formulate an email. However, concrete insights that make such an email really useful are often missing. The example above shows how the software first searches for the correct contact details and then describes an email based on the problem described. Below you can again see where the contact data comes from – from an internal Confluence entry. Of course, users can also ask the AI to adjust the wording or write the email using du, for example.
There are enough use cases – but how do you implement them?
There are three ways to implement such use cases – but only one is really sustainable for companies:
- You train your own language model (large language model)
- Build a retrieval augmented generation system
- Combine a retrieval augmented generation system with an intelligent search
Training your own language model
Many companies are currently dreaming of a large language model with their own data and the question quickly arises: Why don’t we just train an AI with our data?
As a result, companies would have an AI model that would have the company’s expertise. With this expertise, employees would have the opportunity to have their questions answered.
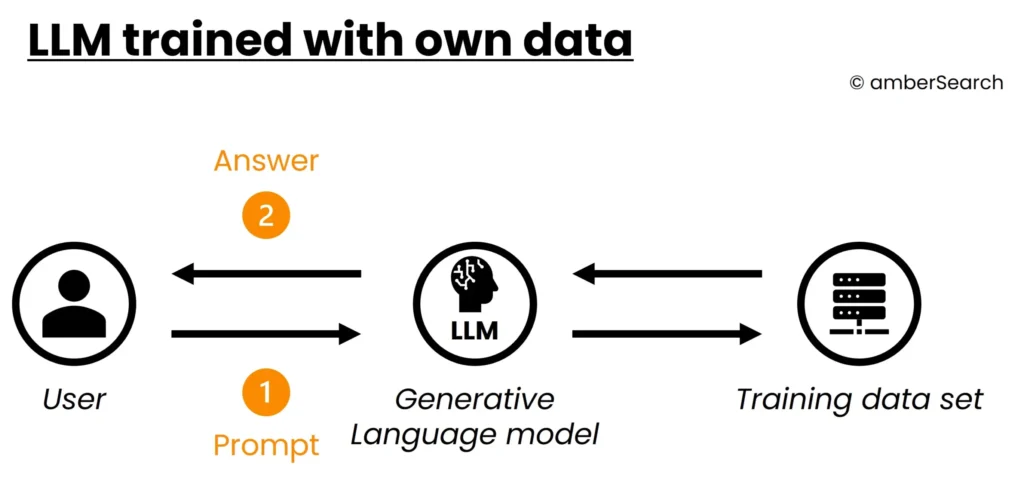
Figure 6: Concept of querying an AI model that has been trained with its own data
However, training an AI model with your own data requires a lot of technical expertise and hardware resources. In total, you are quickly talking about high five- to six-figure sums.
This technical approach also has some disadvantages:
- Firstly, it is necessary to define which data set will be used to train the generative AI.
- As the data set changes quickly, the trained AI model will also be outdated quite quickly.
- As an AI model alone cannot take access rights into account, a rather superficial data set is usually selected. This usually contains too little information to be really specific enough, as the really interesting information is subject to access restrictions and is therefore not used for training
- AI models tend to hallucinate, i.e. the answers are not necessarily correct. If the answers come from the AI model itself (as would be the case with this technical approach) then you would not know where the AI model gets the answer from – similar to ChatGPT.
Use of a retrieval augmented generation approach
However, these challenges could be avoided with the help of a retrieval augmented generation approach. In a retrieval augmented generation approach, before an answer is generated, it is checked which data from a particular data set is best suited to fulfil the user’s request. Only the documents that are judged to be the most relevant are included in the generation of an answer.
To set up a retrieval augmented generation system, a data set would first be defined. This data set would then be indexed or vectorised by the software system.
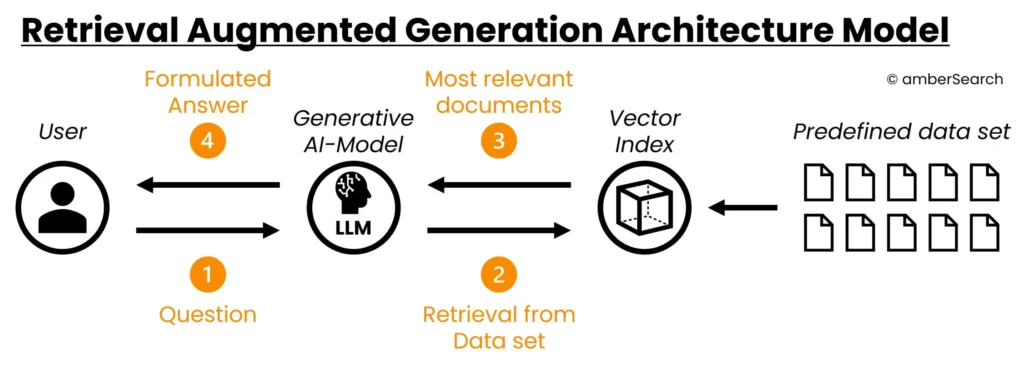
Figure 7: Description of a retrieval augmented generation model without the connection of an enterprise search
If the user now asks a question, the software first looks for the most relevant documents and uses these in combination with the intelligence of an AI model to generate an answer. In this case, the answer is not generated by the expertise of the AI model itself, but by the context provided by the pre-defined data set. The intelligence of the generative AI model is only used to prepare the most relevant results in a form that answers the user’s question. Another advantage of this approach is that its AI model is able to reference where exactly which information comes from.
However, this technical approach also has some unsolved challenges:
- You can use this approach to set up or define various chatbots. You would simply define that a support chatbot gets all the information from support, an onboarding chatbot gets all the information about onboarding and so on. The problem is that you don’t yet have a “truly” comprehensive chatbot, but several specialised chatbots. You have to define a static data set for each use case.
- Access rights are not taken into account here either.
Combination of a retrieval augmented generation system with an enterprise search
In order to make the data set more flexible or to take access rights into account, you should rely on the combination of a retrieval augmented generation system with an enterprise search. The enterprise search, a kind of Google for the company, first searches for all relevant information for the user’s enquiry – taking into account the existing access rights. This information is then passed as context to the generative AI, which is able to process it in such a way that it answers the user’s question. Such a system was also used to generate the screenshots of the various use cases.
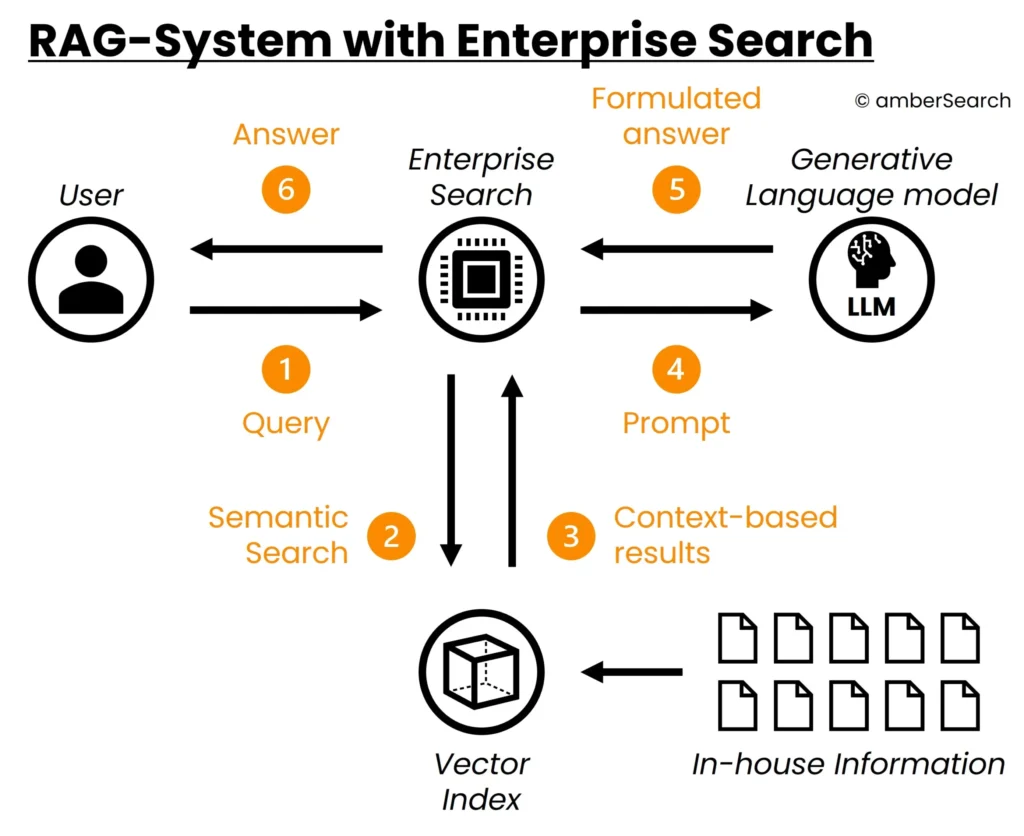
Figure 8: Combination of an enterprise search with generative AI to generate the right answers from a flexible data set
In contrast to the pure retrieval augmented generation system, the enterprise search takes on the task of flexibly defining the data set that matches the prompt. This makes it possible to solve the challenges of multiple retrieval augmented generation systems as well as the challenge of access rights.
However, one challenge of this approach is the following:
- The enterprise search in the background can only focus on one topic of the prompt.
However, in order to solve multidimensional prompts (example in Figure 5, search for contact data and generation of e-mail), a multi-hop question answering system is required. This is able to send several search queries to the system before generating an answer and thus answer the various dimensions of a prompt.
Conclusion – develop it yourself or buy it?
Tools such as ChatGPT and the like make it very easy to build such systems yourself – especially as a small demonstrator. However, if you want a sustainable solution, you should rely on a real product. The aspects already mentioned show that the implementation of such a solution is quite complex and brings with it a number of challenges. There are currently many agencies and consultancies that work with companies to build demonstrators. What companies should bear in mind, however, is the complexity involved in developing such systems themselves. It takes a lot of effort to turn a demonstrator into a productive system, taking into account the challenges mentioned above.
At amberSearch, we started building a product that solves the aforementioned requirements for companies back in 2020, well before the hype surrounding AI.
Frequently asked questions, that are not yet answered by the article:
- What are the potential drawbacks or limitations of implementing generative AI combined with internal company knowledge? While the article discusses the benefits and various applications of using generative AI alongside internal knowledge, it doesn’t delve deeply into the potential downsides or challenges that organizations might face in adopting such technology. Understanding the limitations or potential risks associated with this approach could be crucial for readers considering its implementation.
- Are there any ethical considerations or privacy concerns regarding the use of generative AI with internal company data? Given the sensitive nature of internal company data, readers might wonder about the ethical implications or privacy considerations associated with implementing generative AI systems. Exploring how organizations can ensure data security, privacy compliance, and ethical use of AI technologies would provide valuable insights for readers.
- What steps should businesses take to successfully integrate generative AI solutions into their existing workflows? While the article briefly mentions different approaches to implementing generative AI, it doesn’t offer a detailed roadmap or actionable steps for businesses looking to integrate these solutions into their operations. Readers might be interested in learning about best practices, implementation strategies, and considerations for successful adoption and integration of generative AI technologies within their organizations.