
In den letzten Monaten hat der Begriff “Private KI” immer mehr an Bedeutung gewonnen. Aber was genau ist Private KI, warum wird darüber gesprochen und ist es wirklich die optimale Lösung? Wir tauchen in diesem Artikel tief in die Thematik ein und beleuchten die Frage, ob es sinnvoll ist, Large Language Models (LLMs) mit eigenen Daten zu trainieren.
Inhaltsverzeichnis
Der aktuelle Zustand der generativen KI ist geprägt von Fortschritt und Möglichkeiten. Unternehmen stehen vor der Herausforderung, wie sie die Potenziale dieser Modelle, wie beispielsweise GPT-4, in Kombination mit ihrem internen Know-How am besten nutzen können. Hierbei taucht eine zentrale Frage auf:
Die Herausforderung: Private oder Öffentliche KI?
Wenn Unternehmen sich für den Einsatz von KI-Modellen entscheiden, stehen sie vor der Wahl, diese selbst mit firmeneigenen Daten zu trainieren oder auf die Dienste großer Anbieter wie Google (Bard), OpenAI oder Open Sourcemodellen zurückzugreifen. Die Hürden und Bedenken hierbei sind vielfältig und teilweise durch mangelndes technisches Verständnis begründet. Wir räumen auf!
Wer überlegt, generative KI einzusetzen, der sollte sich unseren Blogartikel zum Thema Einführung generative KI durchlesen.
Was ist eine Private KI?
Private KI beschreibt die Praktik, Algorithmen ausschließlich mit Daten zu trainieren, die einem individuellen Nutzer oder einer Organisation gehören. Wenn ein maschinelles Lernsystem beispielsweise ein Modell auf einem Datensatz von Dokumenten wie Rechnungen oder Steuerformularen trainiert, bleibt dieses Modell alleinig für die internen Zwecke des Unternehmens bestimmt. Der wesentliche Vorteil liegt darin, dass damit vermieden wird, eine gemeinsame Wissensbasis zu schaffen, von der auch potenzielle Wettbewerber profitieren könnten.
Und was ist Öffentliche KI?
Öffentliche KI bezieht sich auf KI-Algorithmen, die auf umfangreichen Mengen öffentlich zugänglicher Daten trainiert werden. Diese Daten stammen in der Regel von verschiedenen Nutzern oder Kunden. Ein bekanntes Beispiel hierfür ist ChatGPT, das auf Informationen aus dem frei verfügbaren Internet wie Textartikeln, Bildern und Videos basiert. Öffentliche KI kann auch Algorithmen umfassen, die Datensätze nutzen, die nicht spezifisch für einen bestimmten Benutzer oder ein bestimmtes Unternehmen sind.
Wer überlegt, solche Technologien in seinem Unternehmen einzusetzen, der sollte vorher unser kostenloses, 16-seitiges White Paper mit allen notwendigen Insights lesen: “So geht eine erfolgreiche Einführung von generativer KI”
Die Illusion des Eigenen: Trainieren mit eigenen Daten?
Viele Unternehmen neigen dazu, den vermeintlich sicheren Weg zu gehen und ein KI-Modell mit eigenen Daten trainieren zu wollen. Sie erhoffen sich, internes Wissen effizient durch ein Frage-Antwort-System zu teilen. Doch hierbei lauern diverse Schwierigkeiten:
- Zugriffsrechte: Ein trainiertes Modell kann keine Zugriffsrechte berücksichtigen, was zu unangemessenen Informationspreisgaben führen kann.
- Datenauswahl: Die Auswahl der richtigen Daten für das Training ist eine komplexe Aufgabe. Wer trifft diese Auswahl und inwiefern sind Zugriffsrechte relevant?
- Kosten: Das Training eigener LLMs erfordert immense Ressourcen und Know-How, was schnell hohe Kosten verursachen kann. Das Training eines eigenen KI-Modells kann schnell in den hohen fünf oder sechstelligen Bereich gehen, wenn man Humankapital und Serverressourcen berücksichtigt.
- Aktualität: Eigenentwickelte Modelle sind oft veraltet, da sie nicht laufend aktualisiert werden. Zudem entwickeln sich externe KI-Modelle rasch weiter. Bei der heutigen Entwicklungsgeschwindigkeit schlagen die öffentlich verfügbaren Modelle schnell selbsttrainierte Modelle, was zusätzlich gegen das Training eines eigenen KI-Modells spricht (Grafik 1). Hier gilt zudem zu beachten, ob das Unternehmen willens ist, langfristig die Ressourcen (Serverressourcen und Humankapital) bereit zu stellen, um ein eigenes KI-Modell im weiter zu trainieren.
- Richtigkeit: Eigene KI-Modelle könnten falsche oder verwirrende Informationen generieren, die aufgrund mangelnder Referenzen nicht überprüfbar sind.
- Know-How: Das nötige Fachwissen für das Training fehlt oft und der Erwerb kann teuer sein.
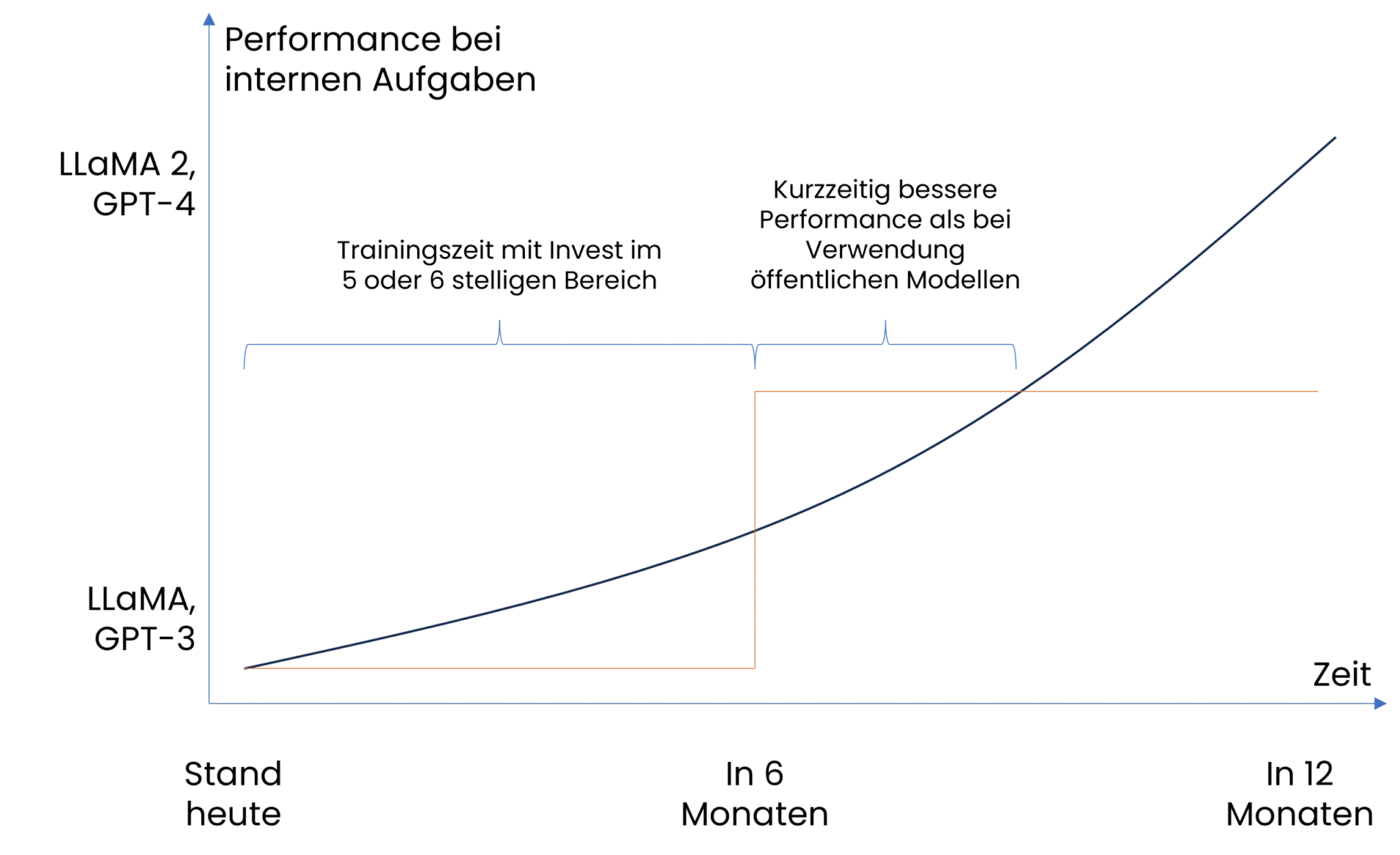
Grafik 1: Performance von privater KI gegenüber öffentlicher KI
Grundsätzlich gilt, dass ein Modell nur so gut wie seine Daten ist. Wenn ausschließlich ein Datensatz ausgewählt wird, welcher aus Daten erstellt wird, die allen Mitarbeitern zugänglich sind, dann wird die Antwort Tiefe nicht sonderlich tief sein. Das führt einerseits dazu, dass das System nicht so stark ist, wie es sein könnte und andererseits Mitarbeiter, die das System weniger oder gar nicht nutzen. Wenn andererseits jedoch „zu viele“ Daten genutzt werden, dann kann es sein, dass bestimmte Mitarbeiter Informationen bekommen, die eigentlich nicht für Sie bestimmt waren (bspw. Umsatz mit einem Kunden etc).
Eine bessere Lösung, um eine private KI zu imitieren: Enterprise Search trifft generative KI
Statt in die Fallstricke des eigenen Trainings zu geraten, bietet sich eine effektivere Alternative an: Retrieval Augmented Generation. Man kann nämlich den Kontext, den eine Enterprise Search – in unserem Fall amberSearch – erkennt nutzen, um diesen als Kontext für ein generatives KI-Modell zu nutzen. Der Vorteil ist, dass die Übergabe des Kontextes so gut wie keine Rechenzeit verbraucht, was dieses Set Up extrem leistungsfähig macht.
Aus technischer Sicht würde die Enterprise Search alle relevanten Informationen unter Berücksichtigung der Aktualität und der Zugriffsrechte raussuchen.
Diese werden dann einem KI-Modell als Kontext übergeben:
Anstatt eine Antwort aus eigenem Wissen (ohne Berücksichtigung von Zugriffsrechten) heraus liefern zu müssen, wird die künstliche Intelligenz des generierenden Modells genutzt, um aus einem definierten Kontext (Zugriffsrechte sind berücksichtigt) die richtige Information zu generieren. Genau das machen wir nämlich mit amberAI.
Um diesen Effekt hinzukriegen, setzen wir auf Public AI – allerdings in einer Open-Source Variante. Die von uns verwendeten Open Source Modelle wurde ohne Kundendaten (!) verfeinert, so dass es perfekt auf die Anwendungsfälle unserer Kunden abgestimmt ist. Wir nutzen also KI-Modelle, die mit öffentlichen Daten trainiert sind, wenden diese aber ausschließlich für interne Anwendungsfälle an. So behalten unsere Kunden die Datenhoheit, können aber das breite Wissen der Öffentlichkeit nutzen, um vergleichbare Effekte wie mit einer Private AI zu nutzen. Anschließend ist nur noch die Frage, wo eine solche Lösung gehostet werden soll.
Damit jeder amberSearch einmal ausprobieren kann, haben wir in unserer Onlinedemo eine mittlere sechsstellige Anzahl an Dokumenten auf über 10 Systeme verteilt:
Mit diesem Ansatz schlagen wir gleich mehrere Challenges, die beim Training eines eigenen KI-Modells entstehen:
- Referenzierung: Wir können darauf verweisen, wo wir welche Informationen gefunden haben, damit der Benutzer überprüfen kann, ob die gefundenen Informationen korrekt sind.
- Aktualität: Durch die KI-unterstützte Suche werden stets aktuelle Informationen gefunden.
- Berücksichtigung der Zugriffsrechte: Zugriffsrechte werden gewahrt und beachtet.
- Kein Training mit eigenem Know-How: Unternehmen müssen keine eigenen KI-Modelle erstellen und trainieren.
- Kosteneffizienz: Die Lösung ist kostengünstig und effizient
- Kein zusätzliches Know-How erforderlich: Durch den Einsatz einer GDPR-konformen Lösung wie amberSearch müssen Sie sich keine Sorgen machen, dass Sie eigene Experten benötigen.
Kurz gesagt: Unsere Alternative funktioniert durch das Zusammenspiel von amberSearch und einem von uns finegetuntem Open-Source KI-Modell, das eine allgemeine Intelligenz besitzt. Die Suche ermittelt relevante Informationen basierend auf Zugriffsrechten und Aktualität. Das generative Modell nutzt den Kontext, um treffende Antworten zu geben, ohne dass es selbst trainiert werden muss.
Und so kann ein Lösungweg wie in diesem Artikel beschrieben dann in der Praxis aussehen:
Abschließend zeigt sich, dass der Weg einer Privaten KI mit einem selbsttrainiertem Modell oft nicht die beste Lösung ist. Die Kombination aus Enterprise Search und generativen KI-Modellen bietet eine bessere und auch kostengünstigere Lösung. Unternehmen sollten nicht in die Falle tappen, unnötig große Mengen an Daten in eigene Modelle zu stecken, wenn eine intelligente Kombination den gewünschten Output liefern kann und durch das Training eigener KI-Modelle vor allen Dingen eine Gruppe von Unternehmen profitiert: Cloudprovider.
Du findest unseren Content spannend?
Dann bleib jetzt über unseren Newsletter mit uns in Kontakt: