Retrieval Augmented Generation (RAG) ist eine leistungsstarke neue NLP-Technik für Suchanwendungen in Unternehmen, welche einen Großteil der Herausforderungen, die klassische generative Large Language Models (LLMs) haben, löst.
Inhaltsverzeichnis
Unternehmen spüren, dass generative KI einen nachhaltigen Einfluss auf unsere Arbeitswelt haben wird und dies nicht nur „ein neuer Hype“ ist. Nachdem es in vielen Unternehmen zunächst die Idee gab, ein eigenes KI-Modell zu trainieren, wurde diese schnell wieder verworfen. Die Aufwände und Nachteile sind einfach zu groß: KI-Modelle sind aktuell zu schnell outdated und Zugriffsrechte werden nicht berücksichtigt. Das macht sie unbrauchbar für unternehmensinterne Anwendungsfälle, in denen Zugriffsrechte und auch die Aktualität der Informationen ein Must-have sind. Mehr dazu in diesem Blogartikel über private KI.
Retrieval-Augmented Generation ist ein Ansatz für die Verarbeitung natürlicher Sprache (NLP), der die Leistungsfähigkeit großer Sprachmodelle (LLM’s) mit der Präzision von Information Retrieval Systemen (Enterprise Search) kombiniert. Zurzeit stürzen sich viele Anbieter auf das Thema, da es aktuell einen extremen Boom erfährt. Um ein solches System aufzusetzen, ist einiges an Know-How erforderlich, welches wir über die letzten Jahre erfolgreich aufgebaut haben. Neben den Anbindungen an die Datenbanken und Systeme des Unternehmens (bspw. SharePoint, Laufwerke & Co – s. Integrationen) müssen auch Zugriffsrechte, inhaltliche Relevanz sowie Aktualität berücksichtigt werden, um gute Ergebnisse liefern zu können. Im Folgenden erklären wir daher die technischen Unterschiede von einem RAG-System zu einem klassischen generativen Ansatz, insbesondere in Bezug auf die Genauigkeit und semantische Suche.
Wer überlegt, solche Technologien in seinem Unternehmen einzusetzen, sollte vorher unser kostenloses, 16-seitiges Whitepaper mit allen notwendigen Insights lesen: „So geht eine erfolgreiche Einführung von generativer KI“:
Einfache Large Language Model-Abfragesysteme
In einem klassischen LLM wird an das generative KI-Modell eine Frage gestellt, welches diese Frage mit dem Wissen aus dem Trainingsdatensatz, mit dem es ausgestattet wurde, beantwortet. Dieser Trainingsdatensatz ist starr und hat ein Cut-off-Datum (bei ChatGPT war dies bspw. lange September 2021, mittlerweile ist es Dezember 2023). Das funktioniert jedoch nur, indem das Modell neu mit relevanten Informationen angereichert wird, d. h. neue Ressourcen investiert werden, um es aktuell zu halten (s. erster verlinkter Blogartikel).

Beispielhafte Antwort eines einfachen LLMs
In unserem Beispiel gibt das LLM eine vollkommen legitime und verständliche Antwort, die jedoch auf dem Wissen basiert, welches bis zum Cut Off Datum abgerufen werden konnte. Zusätzlich wird leider nicht referenziert, woher die Antwort stammt.
Du willst wissen, wie man generative KI erfolgreich ins Unternehmen einführt? Dann lies dir jetzt diesen Blogbeitrag durch!
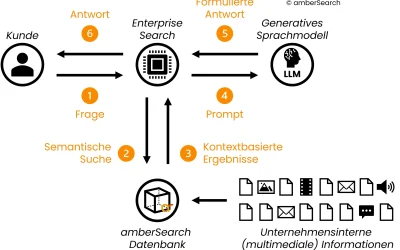
Wie sieht die Architektur für ein klassisches LLM-System aus?
Im Folgenden haben wir die Architektur eines klassischen LLM-Systems simplifiziert abgebildet:
Simplifizierte Darstellung eines LLM’s Abfrageprozesses
In diesem Fall stellt der Nutzer eine Frage an das generative Sprachmodell [1]. Dieses wandelt die Frage bzw. den Prompt in ein für das KI-Modell verarbeitbares Format um und generiert darauf aufbauend eine Antwort [2]. Um diese Antwort zu generieren, greift das KI-Modell auf die Informationsquellen zurück, die ihm ursprünglich bereitgestellt wurden.
Das Problem für sowohl den Nutzer als auch den Entwickler bei klassischen LLM’s ist, dass nicht logisch nachvollziehbar ist, weshalb ein generatives KI-Modell eine Antwort formuliert – es handelt sich also um eine Blackbox. Für Anwender bedeutet das:
- Klassische LLM haben keine Quellen für ihre Antworten, sondern sind nur in der Lage, Wissen wiederzugeben, welches sie über den Trainingsdatensatz „aufgeschnappt“ haben
- Klassische LLM fangen an, Wissen zu kombinieren, was für uns wie Halluzinieren wirkt und dementsprechend nicht zuverlässig ist
- Klassische LLM können keine Fragen mit Wissen außerhalb ihrer Trainingsdaten beantworten, sondern nur Fragen mit den Informationen, die in Ihrem Trainingsdatensatz enthalten sind
- Dadurch, dass der Trainingsdatensatz keine Struktur hat, können Zugriffsrechte oder die Aktualität von Informationen nicht berücksichtigt werden
Mit anderen Worten: LLMs sind leistungsstarke Werkzeuge, aber sie sind nicht perfekt. Sie können eine Abfrage nur auf der Grundlage der Informationen beantworten, auf die sie trainiert wurden, und sie sind nicht immer genau. Bei der Anwendung von LLMs sollten den Nutzern diese Einschränkungen bewusst sein. Im unternehmensinternen Gebrauch sind die genannten Schwachstellen jedoch so gravierend, dass Sie einen großflächigen internen Einsatz von generativen KI-Modellen in den meisten Anwendungsfällen nicht nachhaltig machen.
Retrieval Augmented Generation System
In einem Retrieval Augmented Generation System wäre die Antwort präzise und basierend auf abgerufenen Informationen wie folgt formuliert:
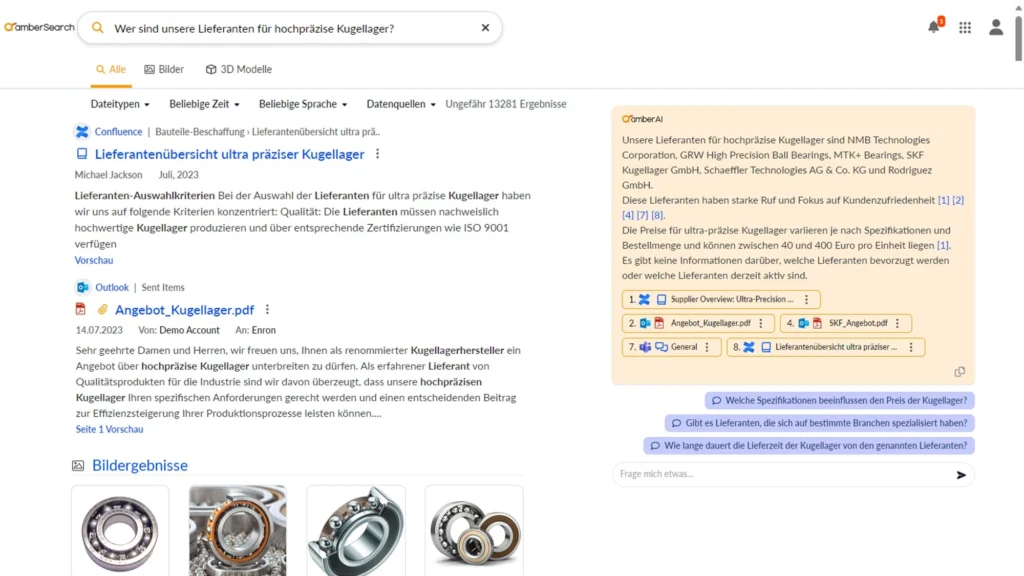
Screenshot aus unserer Software amber. Der orange hinterlegte Teil ist die generierte Antwort.
Um den genannten Schwächen von einfachen Sprachmodellen entgegenzuwirken, nutzen wir mit amber eine andere Technik – nämlich Retrieval Augmented Generation. In einem solchen System wird, bevor auf das generative KI-Modell zurückgegriffen wird, zunächst eine Vorfilterung vorgenommen, welche sicherstellt, dass Antworten nur auf relevanten, aktuellen und zugänglichen Informationen generiert werden. Für die Vorfilterung nutzen wir unsere Enterprise Search – amber. Diese ermöglicht uns, verschiedene interne Systeme (Intranets, DMS, M365, Atlassian, etc.) unter Berücksichtigung der Zugriffsrechte anzubinden. Mit amberAI nutzen wir dann die von amber gefundenen Ergebnisse, um eine Antwort passend zur Frage des Nutzers zu generieren. Die Architektur des Modells sieht also folgendermaßen aus:
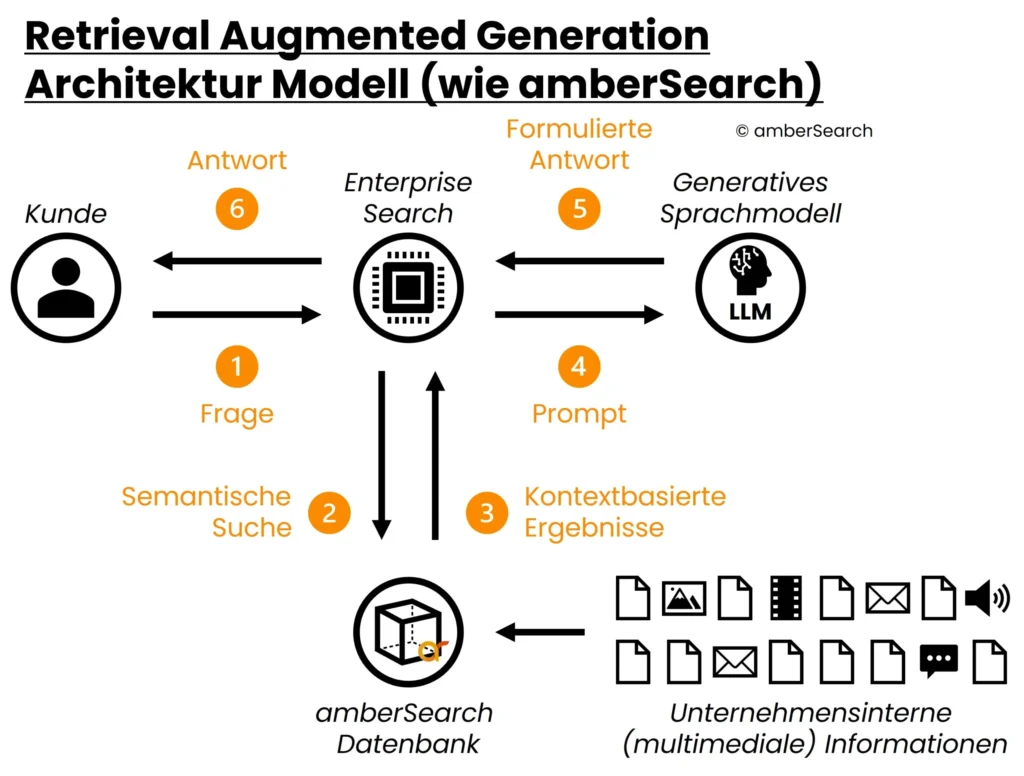
Darstellung der Architektur eines Retrieval Augmented Generation Systems
Zunächst gibt der Nutzer eine Frage in amber ein [1]. amber sucht [2] – unter Berücksichtigung der Zugriffsrechte – in einem Index, welcher die zu durchsuchenden unternehmensinternen Inhalte enthält, die relevantesten Antworten. Dieser Index wird dauerhaft aktualisiert, damit Nutzer immer Zugriff auf die aktuellsten Informationen haben. Diese Ergebnisse werden anschließend von amber in einen Prompt, bestehend aus gefundenen Inhalten sowie der Query [3] [4] an ein generatives KI-Modell gegeben. Dieses formuliert basierend auf dem vorgegebenen Kontext eine Antwort [5], welche über die Enterprise Search an den Nutzer ausgespielt wird [6].
Heruntergebrochen haben wir also 2 Prozesse. Den Prozess, um eine Antwort zu suchen und einen Prozess, um darauf aufbauend eine Antwort zu generieren.
In unserem Onlinedemosystem haben wir eine mittlere sechsstellige Anzahl an Dokumenten auf über 11 Systeme verteilt, damit jeder ein Gefühl dafür bekommen kann, wie amber funktioniert:
Um den ersten Schritt erfolgreich zu lösen, haben wir unser eigenes KI-Modell trainiert, welches wir bereits 2020 (!) Open-Source gestellt haben. Dieses hat mittlerweile über 200.000 Downloads erhalten und wurde in mehreren unabhängigen Studien als eines der am stärksten, verfügbaren deutschsprachigen Modelle am Markt eingestuft (Quelle 1-5). Intern sind wir mittlerweile einige Iterationen weiter, die wir nicht mehr Open-Source gestellt haben. Als Basis dafür dient unsere amber Vektordatenbank. Dies ist eine Datenbank, die auf Vektoren basiert, in der wir Informationen aus Dokumenten, Bildern, Videos und anderen multimedialen Inhalten speichern können. Auch hier sind wir der einzige uns bekannte Anbieter, der solche Funktionen in dieser Art und Weise anbieten kann.
Fun Fact: LLMs, so wie wir sie heute kennen, wurden von Google zunächst im Jahr 2017 auf der Neural Information Processing Systems Konferenz in Los Angeles vorgestellt. Bei amber haben wir das Potenzial als eines der ersten Unternehmen in Deutschland erkannt und eines der ersten deutschsprachigen Sprachmodelle trainiert. Somit gibt es in Deutschland kaum ein Unternehmen, welches länger Erfahrung im Bereich LLMs als wir hat.
Für den zweiten Schritt (amberAI) verwenden wir ebenfalls ein eigenes KI-Modell, welches wir auf die Bedürfnisse unserer Kunden angepasst haben. Weiterführende Informationen zu unseren Entwicklungsgrundsätzen für amberAI haben wir auf unserer Supportseite hinterlegt.
Die nächste Ausbaustufe zu Retrieval Augmented Generation ist übrigens Multi-Hop Q&A.
RAG vs einfaches LLM: Unterschiede & Vorteile von RAG
RAG vs einfaches LLM: Unterschiede & Vorteile von RAG
In der folgenden Tabelle haben wir die wichtigsten Unterschiede eines einfachen LLM zu einem Retrieval Augmented Generation System dargestellt.
| Retrieval Augmented Generation System | Einfaches Large Language Modell |
| Keine Halluzinationen: Dadurch, dass Retrieval Augmented Generation Systeme auf einen gegebenen Kontext zurückgreifen, ist das Risiko für Halluzinationen deutlich geringer. | Die Generierung einer Antwort basierend auf dem Wissen von Large Language Modellen bedeutet, dass verschiedene Informationen vermischt werden, was zu Halluzinationen führt. |
| Referenzieren: Mit diesem kontextbasierten Ansatz sind wir in der Lage, die Herkunft von Informationen zu referenzieren, sodass Nutzer und Entwickler nachvollziehen können, wie Antworten zustande kommen. | Dadurch, dass darauf gesetzt wird, dass das Wissen aus dem KI-Modell selbst kommt, ist nicht nachzuvollziehen, weshalb eine bestimmte Antwort generiert wird. |
| Training von KI-Modellen: Mit diesem Ansatz müssen KI-Modelle nicht auf Kundendatensätzen nachtrainiert werden. Es wird nur die allgemeine Intelligenz dieser Modelle genutzt, um zu verstehen, worum es in den Dokumenten geht, um diese zu bewerten bzw. Antworten zu liefern. | Wenn die KI-Modelle nicht mit einem guten Trainingsdatensatz ausgestattet werden, dann kommen keine guten Ergebnisse raus. Zusätzlich ist quasi schon mit Liveschaltung (aufgrund von Trainingsdauer) das Modell wieder Outdated. Es müssen konstant Ressourcen bereitgehalten werden, um das KI-Modell nachzutrainieren. |
| Austauschbarkeit von KI-Modellen: Aktuell werden beinahe tägliche neue KI-Modelle und weitere Optimierungen veröffentlicht, die jedes individuelle Trainieren (auch unter Berücksichtigung von notwendigen Ressourcen) innerhalb kürzester Zeit überholen. Mit einer Architektur, in der KI-Modelle nicht kundenspezifisch trainiert werden müssen, sind KI-Modelle deutlich schneller austauschbar und so deutlich einfacher auf dem Stand der Technik zu halten als individualisierte Systeme. | Um neuere KI-Modelle einsetzen zu können, müssen erneut Ressourcen für das Training bzw. die Auswahl des Datensatzes, Implementierung etc. aufgebracht werden. |
| Zugriffsrechte, Aktualität & Relevanz: Durch das Vorschalten einer intelligenten Suche wie amber wird sichergestellt, dass ein Nutzer ausschließlich die Informationen findet, auf die er wirklich Zugriff hat. Zusätzlich ist amber in der Lage, Relevanz und Aktualität in die Bewertung der Ergebnisse einfließen zu lassen, was die Qualität der Ergebnisse weiter verbessert. | Dadurch, dass Antworten aus dem Wissen des KI-Modells generiert werden, ist dieses nicht in der Lage, Informationen wie Aktualität, Relevanz oder Zugriffsrechte zu berücksichtigen. |
| Starrer vs. Flexibler Datensatz: Über den Retrieval Augmented Generation Ansatz können individuelle Inhalte u. a. auch aus Mails, Teams-Nachrichten oder anderen zugriffsbeschränkten Inhalten DSGVO-konform genutzt werden. Somit kann ein System für verschiedenste Anwendungsfälle, bspw. im Kundenservice, dem Vertrieb oder der Entwicklung genutzt werden. | Dadurch, dass ein klassisches LLM auf einem starren Trainingsdatensatz basiert, muss für jeden Anwendungsfall ein neuer Datensatz definiert sowie ein neues KI-Modell trainiert werden. Das kostet unfassbare Ressourcen und verhindert einen nachhaltigen Einsatz von generativer KI in Unternehmen. |
| Sicherheit & Datenschutz: Die Architektur von Retrieval Augmented Generation Systemen bedeutet, dass kein KI-Modell mit kundenspezifischen Informationen nachtrainiert werden muss. Dadurch hat ein Unternehmen einen deutlich besseren Überblick darüber, was mit seinen Daten passiert. | Um ein eigenes LLM trainieren zu können, müssen Unternehmen zumindest einen Teil Ihres Know-Hows für das Training eines KI-Modells freigeben. Dies birgt ein gewisses Risiko, dass Know-How abfließt. |
| Schwächen ausgleichen: Dieser Ansatz kombiniert mehrere KI-Modelle miteinander, um die Schwächen der unterschiedlichen KI-Modelle auszugleichen. | Basiert nur auf einem KI-Modell und hat keine Möglichkeit, die eigenen Schwächen (Halluzination, Aktualität, Zugriffsrechte, …) auszugleichen. |
Contextual RAG – die nächste Entwicklungsstufe
Klassisches RAG, so wie in diesem Blogartikel beschrieben, ist die Grundlage für viele KI-Plattformen. Mittlerweile hat sich der Ansatz jedoch deutlich weiterentwickelt. Wie genau, das erklärt unser Blogartikel zum Thema Contextual RAG.
Du findest unseren Content spannend?
Dann bleib jetzt über unseren Newsletter mit uns in Kontakt:
Was macht amber einzigartig?
Ein solches System aufzusetzen ist nicht ganz einfach und bedarf einiges an Know-How. Bei amber bieten wir beide genannten Prozessschritte (Suche und Generierung von Antworten) aus einer Hand, ohne von Drittanbietern abhängig zu sein. Dies gibt uns die volle Kontrolle über unsere Pipeline und ermöglicht uns, an jeder Stelle Anpassungen vorzunehmen. Andere Anbieter besitzen entweder nicht die Möglichkeit, ihre Chatsysteme mit internen Datenquellen zu kombinieren bzw. müssen auf Drittanbieter wie Google Bard, OpenAI oder Aleph Alpha setzen, um die generative KI anbieten zu können. Zusätzlich können wir nicht nur mit Textinformationen umgehen, sondern auch mit multimedialen Inhalten – also Informationen, die in Bildern, eingescannten Dokumenten, Videos & Co gespeichert sind. Schau dir folgendes Video an, um zu erfahren, wie amberAI aussehen kann, oder probiere unsere Lösung direkt in unserer kostenlosen Onlinedemo mit einem Demodatensatz von über 200.000 Dokumenten aus!
Du willst mehr erfahren? Dann stelle hier eine Kontaktanfrage an uns und wir melden uns so schnell wie möglich bei dir:
Quellen
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9090691
- https://www.scitepress.org/Papers/2023/118572/118572.pdf
- https://www.researchgate.net/publication/365493391_Query-Based_Retrieval_of_German_Regulatory_Documents_for_Internal_Auditing_Purposes
- https://arxiv.org/pdf/2205.03685.pdf
- https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=3787&context=dissertations_2
- https://link.springer.com/article/10.1007/s10791-022-09406-x