
Seit Jahren dominieren Knowledge Graphen als Technologie, wenn es darum geht, Wissen in Unternehmen abrufbar zu machen. Knowledge Graphen dienen dazu, unstrukturiertes Wissen zu strukturieren und das Wissen darüber abrufbar zu machen. Dabei hat das Wort „Wissensmanagement“ in vielen Unternehmen viel verbrannte Erde hinterlassen. Doch in den letzten Jahren haben sich Large Language Modelle (LLM’s) etabliert. Unternehmen, die überlegen, im Wissensmanagement (wieder) aktiv zu werden, haben also die Qual der Wahl: setzen Sie auf eine etablierte Technologie oder auf eine moderne, sich weiterentwickelnde Technologie. Ohne eine genauere Betrachtung der beiden Technologien ist eine Bewertung kaum möglich.
Inhaltsverzeichnis
Was sind LLM’s (wenn sie für den Anwendungsfall Wissensmanagement eingesetzt werden)?
LLM steht für “Large Language Models”, also große Sprachmodelle, die auf künstlicher Intelligenz basieren und ein breites Verständnis und Generierung von menschenähnlicher Sprache ermöglichen. Wenn sie im Bereich des Wissensmanagements eingesetzt werden, dienen sie dazu, Informationen zu organisieren, zu verstehen, zu verarbeiten und zu generieren.
LLM’s in der Form, wie man sie heute kennt (Transformermodelle), wurden erst 2017 entwickelt. Damals wurden sie in einem wissenschaftlichen Stadium als sogenannte Transformer Modelle auf der NIPS in Las Vegas von Google vorgestellt. Seit 2020 beschäftigen wir uns bei amberSearch mit dieser Technologie und haben bereits einige Modelle veröffentlicht. Seit der Veröffentlichung von ChatGPT durch OpenAI im November 2022 hat sich die Technologie noch schneller als vorher weiterentwickelt und Unternehmen setzen diese nun in der breite ein.
Im Kontext des Wissensmanagements können LLM’s verschiedene Anwendungsfälle lösen, zu denen meistens die folgenden gehören:
- Semantische Suche: Durch ihr Verständnis natürlicher Sprache können LLM’s eine fortschrittliche semantische Suche ermöglichen. Das heißt, sie können nicht nur nach Schlüsselwörtern suchen, sondern auch den semantischen Kontext verstehen und relevante Ergebnisse liefern. amberSearch ist ein Lösungsbeispiel für diesen Anwendungsfall.
- Frage-Antwort-Systeme: Sie können als Grundlage für Frage-Antwort-Systeme dienen, indem sie natürlichsprachliche Fragen verstehen und präzise Antworten generieren. Dies ermöglicht eine effiziente Informationsabfrage und unterstützt Mitarbeiter:innen bei der schnellen Beschaffung von Informationen. amberAI ist ein Lösungsbeispiel für diesen Anwendungsfall.
- Informationsextraktion und Zusammenfassung: LLM’s können große Textmengen analysieren, wichtige Informationen extrahieren und diese zu prägnanten Zusammenfassungen kondensieren. Das hilft dabei, große Datenmengen zu verarbeiten und relevante Erkenntnisse herauszufiltern. Auch in diesem Fall ist amberAI ein Lösungsbeispiel.
- Personalisierte Empfehlungen: Basierend auf den Interaktionen und Präferenzen der Benutzer:innen können LLM’s personalisierte Empfehlungen für Inhalte oder Informationen geben, indem sie Muster in den Daten erkennen und entsprechende Vorschläge machen. Auch solche Funktionen stecken in amberAI.
- Textgenerierung und Dokumenterstellung: LLM’s können dazu verwendet werden, automatisch Berichte, Dokumente oder Artikel zu generieren, indem sie Informationen aus verschiedenen Quellen synthetisieren und in verständlicher Sprache präsentieren.
Vorteile von LLM’s im Wissensmanagement:
- Sprachverständnis und Interpretation: LLM’s können Informationen in natürlicher Sprache verstehen und interpretieren, was die Interaktion mit Wissensressourcen intuitiver und benutzerfreundlicher macht.
- Aktualität: Durch die Kombination mit Techniken wie Retrieval Augmented Generation oder Multi-Hop-Question Answering haben LLM’s immer Zugriff auf das aktuellste Wissen, ohne dass dieses vorher antrainiert werden muss.
- Out-of-the-Box Systeme: Richtig eingesetzt funktionieren Large Language Modelle Out-of-the-Box und bedürfen keinem individuellen Training oder Tagging.
Nachteile von LLM’s im Wissensmanagement:
- Interpretierbarkeit und Transparenz: Die Entscheidungen von LLM’s basieren auf komplexen Modellen, was ihre Entscheidungsprozesse weniger transparent und schwerer nachvollziehbar macht. Aber mit Retrieval Augmented Generation Techniken können diese gelöst werden.
- Verzerrungen und Fehlinterpretationen: Es besteht die Möglichkeit, dass LLM’s aufgrund ihrer Trainingsdaten und Algorithmen verzerrte oder fehlerhafte Informationen generieren können, was zu falschen Interpretationen oder Antworten führt.
- Hohe Rechenleistung und Ressourcenbedarf: Die Verwendung von LLMs erfordert erhebliche Rechenleistung und Ressourcen, um effektiv zu funktionieren, was abhängig von der Art des Hostings nicht für alle Organisationen verfügbar bzw. kosteneffizient ist.
Was sind Knowledge Graphen?
Knowledge Graphen sind eine innovative Art, Informationen und deren Beziehungen zueinander darzustellen. Stell sie dir wie eine riesige Netzwerkkarte vor, die Datenpunkte (wie Personen, Orte, Konzepte) miteinander verbindet, um deren Beziehungen und Bedeutungen zu verdeutlichen.
Sie bestehen aus Entitäten (Dinge oder Konzepte) und deren Attributen (Eigenschaften) sowie den Beziehungen zwischen den Entitäten. Zum Beispiel: Eine Entität könnte “Eiffelturm” sein, mit Attributen wie “Höhe”, “Baujahr” usw. und Beziehungen zu anderen Entitäten wie “befindet sich in Paris”.
Knowledge Graphen sind dabei als ausgereifte Technologie zu betrachten, da sie auf dem sogenannten Resource-Description-Framework (RDF) aufsetzen. Dies hat über die Jahre mehrere Updates erhalten, wobei das letzte signifikante Update über 10 Jahre (2014) alt ist.
Wer sich stärker mit einer potenziellen Einführung von LLM’s zum Knowledge Management beschäftigen möchte, der sollte diesen Blogbeitrag lesen.
Damit jeder amberSearch einmal ausprobieren kann, haben wir in unserer Onlinedemo eine mittlere sechsstellige Anzahl an Dokumenten auf über 10 Systeme verteilt:
Was sind die Vorteile von Knowledge Graphen?
- Struktur: Bieten strukturierte Informationen, die klar definiert sind und Beziehungen zwischen Entitäten zeigen.
- Transparenz: Bieten ein transparentes Modell, das leichter zu verstehen ist, da es die Beziehungen zwischen Datenpunkten explizit darstellt.
- Darstellung: Bieten klare Darstellungen von Wissen, das in einem speziellen Bereich oder einer Domäne existiert.
Was sind die Nachteile von Knowledge Graphen?
- Erstellung: Die Erstellung von Knowledge Graphen ist zeitaufwendig, da die Zusammenhänge einmal definiert werden müssen. Das Wissen muss in vordefinierte Schemata gegeben werden, was es nicht zu einer dynamischen Technologie macht.
- Geringere Flexibilität: Sind möglicherweise nicht so flexibel wie Sprachmodelle und können Schwierigkeiten bei unvorhergesehenen Anfragen haben. Zusätzlich sind sie relativ schwierig auf verschiedene Anwendungen anzupassen, da das „Wissen“ dann wieder neu bzw. anders definiert werden muss.
- Starrheit: Knowledge Graphen sind begrenzt auf das gelernte Wissen und haben Schwierigkeiten neue oder sich entwickelnde Informationen zu integrieren.
Technologieentscheidung: Vergleich LLM’s vs. Knowledge Graphen im Wissensmanagement
Nachdem nun klar ist, was die Vor- und Nachteile von LLM’s sowie von Knowledge Graphen sind, werden die Technologien nun für den Anwendungsfall Wissensmanagement verglichen.
Natürlich existieren für den Einsatz von Knowledge Graphen deutlich mehr Success Stories, als dies bei LLM’s der Fall ist. Nicht, weil LLM’s schwächer sind, sondern weil sie einfach so neu sind, dass sie in vielen Unternehmen noch gar nicht in der Tiefe integriert wurden. Das, was LLM’s jedoch oft vorgeworfen wird ist, dass Sie oftmals den Kontext nicht verstünden. Doch genau hier spielt die Flexibilität von LLM’s eben den Vorteil aus. Durch Techniken wie Multi-Hop Question Answering, Retrieval Augmented Generation und Co können LLM’s selbst entscheiden, wie viel mehr Kontext sie benötigen, um Fragen selbstständig richtig zu beantworten (Stichwort autonome Agenten). Und für den Fall, dass der Mitarbeiter nicht mit der Antwort zufrieden ist, kann er einfach nachfragen stellen und sich entsprechende Informationen generieren lassen. Dabei ist es oft ein Trugschluss, dass man LLM‘s zunächst aufwendig mit internen Daten trainieren muss. Bei amberSearch bieten wir Lösungen an, die Out-of-the-Box und ohne Training funktionieren.
Wir haben bereits einiges an Know-How zum Thema Einführung von generativer KI erarbeitet. Dieses Know-How teilen wir in unserem White Paper “So geht eine erfolgreiche Einführung von generativer KI”. Wer das gesamte, 16-seitige White Paper mit allen Insights lesen möchte, der kann sich den ganzen Report hier kostenlos herunterladen:
Auch Knowledge Graphen haben ihre unbestreitbaren Vorteile: Man weiß, wie sie funktionieren und kann sich sicher sein, dass die Antwort richtig sein wird – vorausgesetzt, dass die im Graphen definierten Informationen aktuell und richtig sind.
Um die richtige Technologie zu bestimmen, muss zunächst jedoch der richtige Anwendungsfall definiert werden. Wir haben hier ein Beispiel hochgeladen, um interessierten zu helfen, Ihre Anwendungsfälle zu definieren.
Entwicklungsaussichten und Trends in Zukunft
Aus unserer Sicht ist klar: Wer zukunftsorientiert arbeiten will, der setzt auf LLM’s. Zu groß ist das (Entwicklungs-)potenzial dieser Technologie, insbesondere, wenn man sich die letzten Jahre anschaut. Was viele CTO’s vor ein paar Jahren noch für technisch nicht umsetzbar hielten, ist nun umsetzbar. LLM’s werden immer effizienter, was dazu führt, dass die hohen Ressourcenanforderungen mittelfristig reduziert werden können. Nicht ohne Grund setzen immer mehr Anbieter auf LLM’s und reduzieren den Einsatz von Knowledge Graphen.
Auch Google nutzt Knowledge Graphen. Wir alle kennen Sie als die Informationen, die auf der rechten Seite neben den Suchergebnissen angezeigt werden. Aber: Google experimentiert mit generativer KI in seinen Antworten – und generiert damit deutlich bessere Antworten, als die aktuellen.
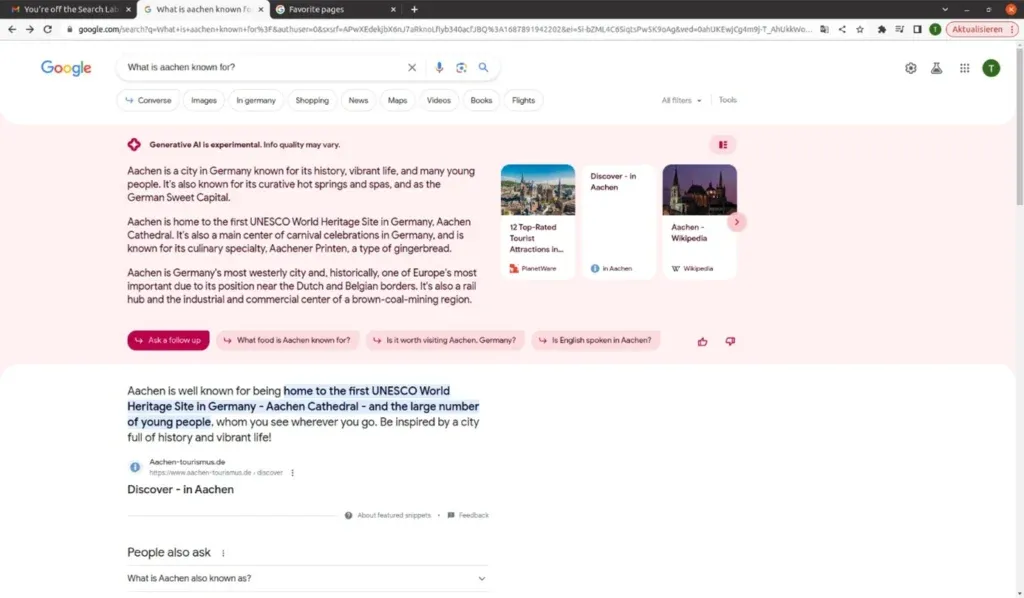
Beispiel wie Google Large Language Modelle in der Suche einsetzt
Am Ende des Tages muss man sich mit beiden Technologien in einer solchen Tiefe beschäftigen, so dass man die potenziellen Mehrwerte, aber auch Ressourcenaufwände realistisch genug abschätzen kann und mit den richtigen Anwendungsfällen eine gute Entscheidung treffen können.
Du findest unseren Content spannend?
Dann bleib jetzt über unseren Newsletter mit uns in Kontakt: