In 2024 hat man das Gefühl, an KI nicht mehr vorbeizukommen. Jeder Softwareanbieter probiert, mal mehr oder weniger sinnvoll, KI in das eigene Produkt zu bringen. Und erste Ergebnisse und Studien zeigen, das Potenzial ist enorm. Doch um das Maximum rauszuholen, müssen die richtigen Entscheidungen getroffen werden und Anwendungsfall, Technik und Mensch gemeinsam miteinander harmonieren.
Inhaltsverzeichnis
Eines der größten Potenziale ist die Kombination von gewachsenen, unternehmensinternen Datensilos mit generativer KI, um das eigentlich vorhandene Know-How für die Mitarbeitenden auch wirklich zugänglich zu machen.
Entscheider stehen jedoch vor der Herausforderung, die richtigen Entscheidungen zu treffen. Aktuell herrscht bei vielen Unternehme(r)n eine Goldgräberstimmung und man will den KI-Hype mitnehmen. Für kaufende Unternehmen geht es darum, langfristig sinnvolle Entscheidungen zu treffen, um einen Überblick im KI-Dschungel zu behalten.
Dieser Blogartikel dient als Leitfaden für Unternehmenslenker und IT-Entscheider, um eine sinnvolle Grundlage für die Einführung und Verwendung von KI im Unternehmen zu entwickeln.
Mit Einblicken in die Technologie, Einsatzfelder sowie einen Blick auf Sicherheitsaspekte und den Menschen gibt dieser Blogartikel einen guten Leitfaden, um eine nachhaltige Entscheidung für das eigene Unternehmen zu treffen.
Was ist künstliche Intelligenz?
Künstliche Intelligenz (KI) ist ein Oberbegriff für alle Methoden, bei denen Computer menschliche Intelligenz und kognitive Fähigkeiten nachbilden. KI ist daher keine spezifische Technologie, sondern eine umfassende Kategorie. Man kann sich das ähnlich wie den Begriff „Kommunikation“ vorstellen. Kommunikation ist die Fähigkeit, Informationen auszutauschen, sagt aber noch nicht, auf welchem Weg dies geschieht.
Nun spricht aktuell zwar jeder über generative KI, aber es gibt diverse Arten der KI.
Eine Art der KI ist zum Beispiel Machine Learning. Wo es früher konkrete, regelbasierte Entscheidungslogiken gab, die zur Lösung von vordefinierten Problemen genutzt werden können (bspw. Taschenrechner), so sind die Prozesse heutzutage deutlich komplexer. Die Herausforderung bei regelbasierter Software ist jedoch, dass Aufgaben nur erledigt werden können, wenn die Logik zuvor in Programmcode geschrieben wurde. Um dieser Herausforderung zu umgehen, kann Machine Learning genutzt werden.
Machine Learning (ML) ist ein Teilgebiet der künstlichen Intelligenz, das Algorithmen und statistische Modelle verwendet, damit Computersysteme Aufgaben ausführen können, ohne explizit programmiert zu werden.
Wer tiefer in die Funktionsweise von KI (in Kombination mit internen Daten) springen möchte, der sollte sich unser Webinar zu diesem Thema ansehen. Die Aufnahme gibt es hier on Demand und kostenlos zu sehen:
Als Entscheidungsgrundlage nimmt das System Informationen aus Daten aus der Vergangenheit, welches in einem sogenannten Training der KI beigebracht wird. Die KI ist anschließend in der Lage, aktuelle Informationen mit den Daten, Trends und Mustern zu vergleichen und darauf aufbauend Entscheidungen oder Vorhersagen zu treffen.
Eine Subkategorie von Machine Learning ist das „Deep Learning“. Sogenannte neuronale Netze – bestehend aus verschiedenen „Schichten“ können noch komplexere Muster in großen Datensätzen erkennen und Lernen. Das „Deep“ in Deep Learning bezieht sich auf die Anzahl der Schichten in den neuronalen Netzwerken.
Mittlerweile sind diese Systeme so gut, dass Sie nicht nur Entscheidungen oder einzelne Vorhersagen treffen können, sondern ganze Texte generieren, verarbeiten, kürzen etc können. Solch verarbeitende Systeme werden anschließend Large Language Modelle (LLM’s) genannt.
Anstatt Texte wirklich zu generieren, berechnen Sie – basierend auf einer Wahrscheinlichkeit – das nächste Wort. So kommt ein KI-generierter Text zustande.
Und mittlerweile beschränkt sich die Generierung solcher Inhalte nicht nur auf Text, sondern erweitert sich auf Bilder, Videos und Audio. Zusammenfassend werden diese Techniken dann generative KI genannt.
Wer sich fragt, was eine KI-Strategie für Unternehmen berücksichtigen sollten und welche Best Practices sich in anderen Unternehmen herauskristallisiert haben, der sollte unbedingt diesen Blogartikel lesen.
Funktionsweise von Large Language Modellen
Letztlich basieren Large Language Models (LLM‘s) auf statistischen Wahrscheinlichkeiten, die aus einem vorherigen Lernprozess resultieren. Ähnlich wie Sie wahrscheinlich beim Satzanfang „Der Himmel ist…” an das Wort „blau” denken, „schätzt” ein LLM kontinuierlich das nächste wahrscheinlich passende (Teil-)Wort basierend auf dem bisherigen Text. In der Praxis wird dieser Schätzprozess für jedes folgende Textsegment wiederholt, bis verwertbare Ergebnisse, in der Regel vollständige Sätze, entstanden sind.
Über verschiedene Techniken ist es möglich, KI-Modellen das Imitieren von Tonalität, Persönlichkeit, etc mitzugeben. Dies sorgt für ein intuitives und vertrauenswürdiges Nutzererlebnis und vermittelt das Gefühl der Kommunikation mit einer echten Person.
Letztendlich sind Large Language Modelle jedoch nur eine Technologie und benötigen eine gute Integration in den Alltag, um Mehrwerte realisieren zu können.
„Eine Softwarelösung wie amberSearch macht die Mehrwerte einer Technologie wie generativer KI erst für Unternehmen realisierbar“
Bastian Maiworm, Geschäftsführer amberSearch
In der Wertschöpfungskette (Hardwareanbieter einmal ausgenommen) stehen unten die KI-Modellanbieter. Ganz oben stehen die Endnutzer (Personen oder Unternehmen), die die Technologie nutzen wollen. Um die Technologie zu nutzen, benötigt es jedoch Softwareanbieter, die eine sinnvolle und vor allen Dingen sichere Integration in bspw. bestehende IT-System ermöglichen. Teilweise gibt es Anbieter wie ChatGPT bzw. OpenAI, die sowohl eigene Modelle trainieren und diese über eine Nutzeroberfläche an Endnutzer anbieten.
Nachteile von Large Language Modellen
Wahrscheinlich haben auch die Leser dieses Blogbeitrags davon gehört – das Training von Large Language Models (LLMs) ist kostspielig und ressourcenintensiv. Der Lernprozess erstreckt sich über mehrere Monate und erfordert neben erheblicher Energiemenge auch hochleistungsfähige Hardware. Nach aktuellen Schätzungen betrugen die Kosten für das Training von OpenAI’s ChatGPT 4.0 beispielsweise etwa 100 Millionen US-Dollar. Aufgrund dieser hohen Kosten und des Aufwands können die Modelle nicht kontinuierlich aktualisiert werden, sondern basieren in der Regel auf den Informationen, die zum Zeitpunkt des Trainings verfügbar waren.
Somit verfügen KI-Modelle über einen statischen Wissensschatz und haben keine direkte Verbindung zum Internet. Um einem KI-Modell diese Informationen zur Verfügung stellen zu können, bedarf es also einem Softwarehersteller, der diese Verbindung herstellt. Eine weitere Schwäche von LLM’s ist das Phänomen des Halluzinierens. Durch die großen Datenmengen „verwechselt“ das KI-Modell manchmal Informationen aus den verschiedenen Schichten. Die Lösung zu diesem Problem wird im weiteren Verlauf des Blogartikels erklärt.
Wer sich stärker für die technischen Finessen von generativer KI in Kombination mit unternehmensinternen Daten interessiert, der sollte unbedingt diesen Blogartikel lesen.
So finden Unternehmen den richtigen Anwendungsfall von KI
Um immer effizienter zu agieren, streben Unternehmen nach einer hohen Automatisierung, um die Skalierung zu erleichtern und um Kosten zu senken. Gerade in der Automatisierung der Kommunikation und des Wissenmanagements bieten LLM’s große Potenziale und viele neue Möglichkeiten.
Der große Vorteil von KI liegt in der Flexibilität von LLM’s. Schließlich wird nicht mehr zwangsläufig eine spezifische Software benötigt, um Probleme zu lösen, sondern man kann mit deutlich generischeren Lösungen wie amberSearch (Teil-)automatisierungen, Wissenstransfer und Co erreichen.
Generative KI kann bspw. bei der Auswertung des eigenen E-Mailpostfachs bzw. bei der Erstellung von Verträgen und Präsentationen helfen. Aber auch in der Konstruktion oder im Vertrieb können KI-Modelle mit Zugriff auf internes Know-How ein wichtiger Rat- und Impulsgeber sein.
Einer Studie der Harvard Business School zufolge konnten Mitarbeiter, die ein Large Language Model (LLM) zur Unterstützung bei ihren Aufgaben nutzten, ihre Aufgaben 25% schneller und mit 40% höherer Qualität erledigen. Diese bemerkenswerte Steigerung der Produktivität verdeutlicht das immense Potenzial solcher Technologien.
Angesichts der vielfältigen Möglichkeiten fällt die Identifikation der richtigen Anwendungsfälle mit den größten Potenzialen daher oft schwer. Daher sollte man sich zunächst einen zentralen Überblick über die verschiedenen Einsatzmöglichkeiten von LLM’s in Unternehmen zu überblicken. Dabei gibt es zunächst zwei grobe Kernbereiche, in denen LLM’s eingesetzt werden können:
| Arbeiten mit Text: | Arbeiten mit Wissen: |
| – Neue Texte erzeugen – Texte sprachlich und stilistisch verbessern – Texte zusammenfassen und paraphrasieren – Texte analysieren und interpretieren – Verschiedene Texte kombinieren und integrieren – Texte übersetzen und lokalisieren | – Große Datenmengen nach relevanten Informationen durchsuchen – Kernaussagen und KPIs extrahieren und darstellen – Wissen und Quellen systematisch strukturieren – Zusammenhänge und Muster in Daten erkennen – Schnelle und präzise Antworten auf komplexe Fragen erhalten – Prognosen und Trends basierend auf historischen Daten vorhersagen |
* Um falsche Erwartungen vorzubeugen: Unsere Lösung amberSearch ist nicht auf jedes dieser Themenfelder spezialisiert. Gerne unterstützen wir jedoch im Gespräch mit weiteren Informationen zu unserer Lösung.
Beispiele aus der Praxis:
Bei amberSearch haben wir mittlerweile dutzende Projekte im Bereich der (generativen) KI durchgeführt. Einige der Anwendungsfälle, die für Unternehmen am interessantesten sind, sind die folgenden:
- Kundendienst – Automatisierung von Antworten auf häufig gestellte Fragen durch Chatbots – entweder auf der Webseite für Endanwender oder Servicetechniker, die beim Kunden sind.
- Personalwesen – Automatisierte Erstscreenings von Lebensläufen und Vorbereitung der Gespräche mit Bewerbern.
- Wissensmanagement – Automatische Strukturierung vorhandener Dokumente und Informationen, auch über viele Jahre und sprachübergreifend.
- Mitarbeiter – Beantwortung wiederkehrender Fragen und Unterstützung beim Onboarding.
- Marketing – Generierung kreativer Inhalte wie Werbetexte, Social-Media-Beiträge oder Blogartikel.
- Vertrieb: Erstellung personalisierter Verkaufs-E-Mails und Chatunterstützung für Vertriebsmitarbeiter. Interne Recherche nach Referenzen und Kundenkommunikation
- Recherche & Suche – Schnelleres Finden von relevanten Informationen in großen Datenmengen.
- Finanzen – Analyse von Finanzberichten und Generierung von Berichtszusammenfassungen.
- Softwareentwicklung – Prüfung, Korrektur oder Generierung von Code.
- Schulung und Entwicklung – Entwicklung interaktiver und personalisierter Lernmaterialien und -kurse.
- Übersetzungsdienste – Schnelle und kostengünstige Übersetzungen von Dokumenten oder Kommunikation für internationale Geschäfte.
- Datenanalyse – Erklärung komplexer Datensätze und Zusammenfassung von Analysen in verständlicher Sprache.
- E-Mail Management – Automatisierung der Priorisierung und Beantwortung eingehender E-Mails.
- Kundenfeedback-Analyse -Extraktion und Analyse von Stimmungen und Meinungen aus Kundenbewertungen.
- IT-Management – Automatisierung der Erstellung und Verwaltung von Dokumentationen für Software und Systeme.
- Vertragsmanagement – Automatisches Extrahieren von Informationen aus Verträgen zur Leistungsüberwachung.
- Content Curation – Unterstützung bei der Auswahl und Zusammenstellung von Inhalten.
Wer sich jetzt fragt, wo er am besten anfängt, der liest am besten unseren Blogartikel „KI-Anwendungsfälle identifizieren und priorisieren“. Dort haben wir weitere wertvolle Insights verarbeitet.
Falls du ein Gefühl für eine solche Lösung bekommen möchtest, dann wirf jetzt einen Blick in unsere Demo. Dort haben wir eine mittlere sechsstellige Anzahl an Dokumenten auf über 10 Systeme verteilt:
Integration mit internen Daten
Wer bis hier hin aufmerksam gelesen hat – der wird erkannt haben: Um die Technologie sinnvoll einzusetzen, bedarf es einer guten Integration in bestehende IT-Systeme, die oftmals gewachsen sind und aus diversen (teilweise selbstentwickelten) Datensilos bestehen. Und natürlich sind diese nicht alle ausschließlich als Clouddienste vorhanden, sondern eine Menge der Informationen liegt auch On-Premise.
Für die meisten Anwendungsfälle werden nämlich Informationen aus unternehmensinternen Inhalten benötigt. Natürlich könnten Nutzer der Software Texte zwischen den Kernanwendungen wie Outlook, einem DMS oder einem Projektmanagementtool in das Chatsystem kopieren. Deutlich praktischer wäre jedoch eine Integration in bestehende Systeme – sowohl in der Nutzeroberfläche als auch zu den Datenbanken der Systeme.
Ein Großteil der KI-Projekte wird scheitern, wenn entweder die Integration in bestehende Datensilos nicht ausreichend ist (schlechte Qualität der Antworten) oder die Integration in bestehende Nutzeroberflächen nicht stimmt (zu geringe Nutzung durch Nutzer)
Bastian Maiworm, Geschäftsführer amberSearch
Gerade bei der Arbeit mit internen Systemen gibt es enorme Potenziale zur Produktivitätsgewinnung, wie eine Studie von McKinsey heraus fand: Wissensarbeiter verbringen 1,8 Stunden täglich mit der Suche nach internen Informationen. Wir haben ähnliche Umfragen unter unseren mittelständischen Kunden – jedoch über alle Abteilungen mit Computerarbeitsplätzen hinweg – gemacht. Dort sind tägliche Suchzeiten von ca. 30 Minuten herausgekommen – ein Wert, der in den letzten Jahren um 77% gestiegen ist und mit der zunehmenden Digitalisierung weiter steigen wird. Bei 400 Mitarbeitenden lässt sich daraus schnell ein Business Case von über eine Millionen eingesparten Euro mit dem richtigen Tool rechnen.
Integration: Wie man interne Daten mit KI kombinieren kann
Nachdem nun eine gewisse Grundlage geschaffen und ein Verständnis für den Einsatz von KI im Unternehmen geschaffen worden ist, geht es nun um verschiedene Möglichkeiten zur Integration eines LLM’s mit den eigenen Daten. Auch wenn in diesem Kapitel nicht explizit auf die DSGVO- und Datenschutzkonforme Umsetzung eingegangen wird, wäre die konkrete Umsetzung unter diesen Richtlinien zwingend erforderlich.
Grundsätzlich gilt: die Herausforderung liegt heutzutage weniger in der technischen Integration dieser Systeme. Wichtiger ist der Mensch, welcher nicht vergessen werden sollte.
Option 1: Bestehende LLM’s als Chatbot bereitstellen
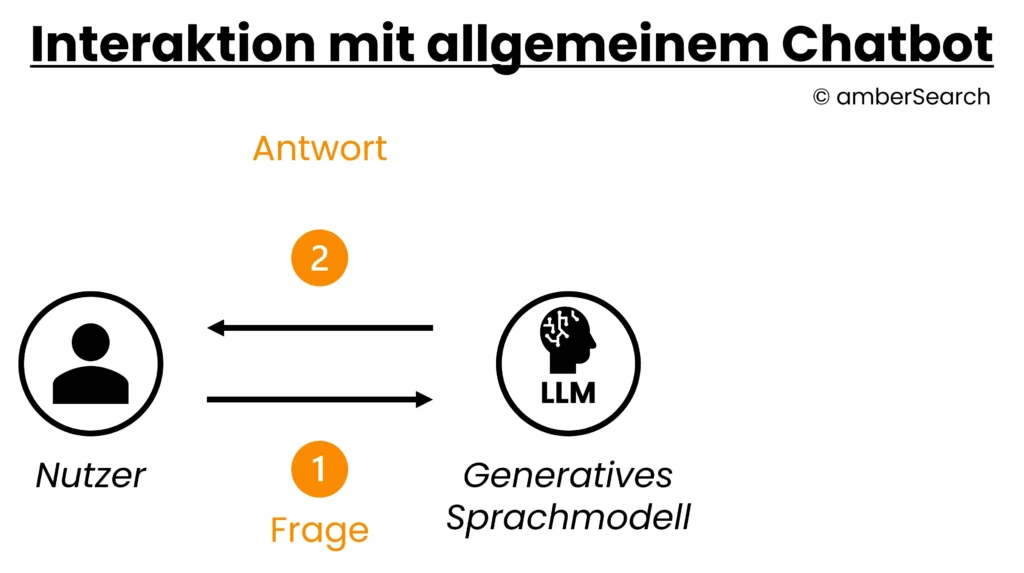
Darstellung der Interaktion mit einem einfachen KI-Chat
Die einfachste Integration in den Arbeitsalltag ist die bloße Bereitstellung eines Chatbots als Nutzeroberfläche in ihren eigenen Systemen – bspw. als Teamsapp. Wenn Unternehmen ihren Mitarbeitenden Zugriff auf einen Chatbot geben, dann haben diese die Möglichkeit, dort Informationen hineinzukopieren und den Chatbot darauf aufbauend Aktionen ausführen zu lassen. Die LLM-Funktionen wären dann jedoch eine eigenständige Lösung und es besteht keine Integration zu den bestehenden Datensilos. Auch wenn diese Lösung sehr schnell und einfach zu implementieren ist, fehlen sämtliche für Unternehmen relevante Überwachungs- und Analysemöglichkeiten.
Option 2: In bestehende Systeme integrierte KI-Funktionen
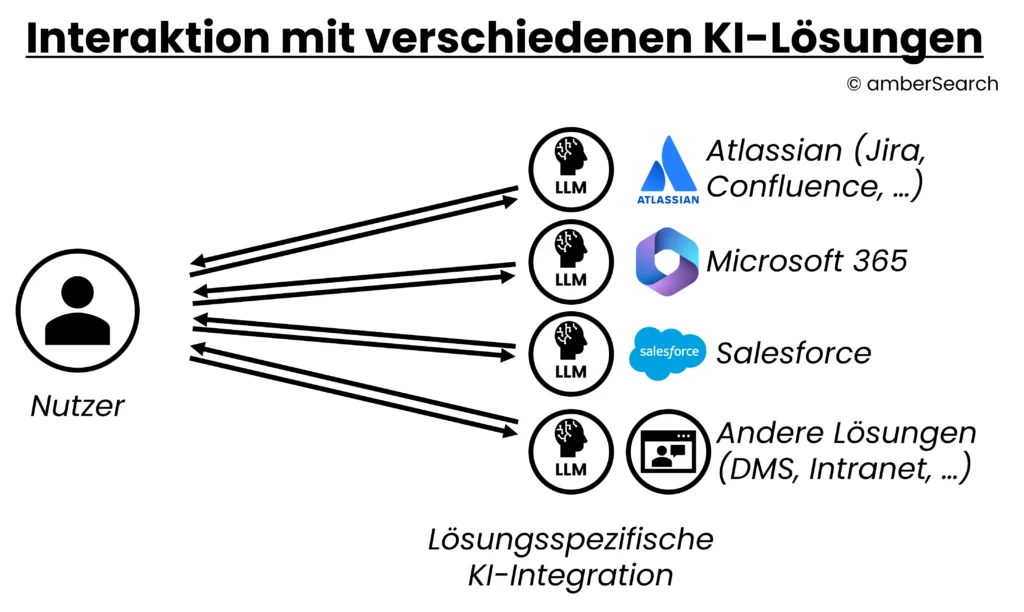
Darstellung einer Integration, bei der man von jeder Applikation die native KI-Integration nutzt
Mittlerweile gibt es kaum einen Softwareanbieter, der nicht seine eigene AI entwickelt. Unternehmern können diese tiefen Integrationen nutzen, um mit den Daten des Systems zu chatten. Als Beispiel könnte ein DMS-Anbieter eine „DMS-AI“ anbieten, mit der Sie dann auf DMS-Daten chatten können. Der Vorteil für die Anwender ist klar: wenn das LLM direkt in die jeweilige Geschäftsanwendung integriert ist, dann besteht automatisch eine Datenintegration und es gibt keinen Medienbruch, da Nutzer nicht zwischen ihrer gewohnten App und einem Chatbot externen wechseln müssen.
Auch wenn man damit eine tiefe Integration in ein System hat, ist die KI noch lange nicht systemübergreifend eingebunden – was jedoch die Erwartung der meisten Nutzenden entspricht. Und auch der Einkauf wird früher oder später fragen, ob ein eigenes KI-System für jedes Tool notwendig ist bzw. ob alle Mitarbeitende bei hohen Extralizenzkosten Zugriff darauf benötigen. Dies würde zu einer weiteren „Zerstückelung“ der IT-Landschaft führen.
Option 3: Eigene LLM’s bzw. Finetuning mit eigenen Daten
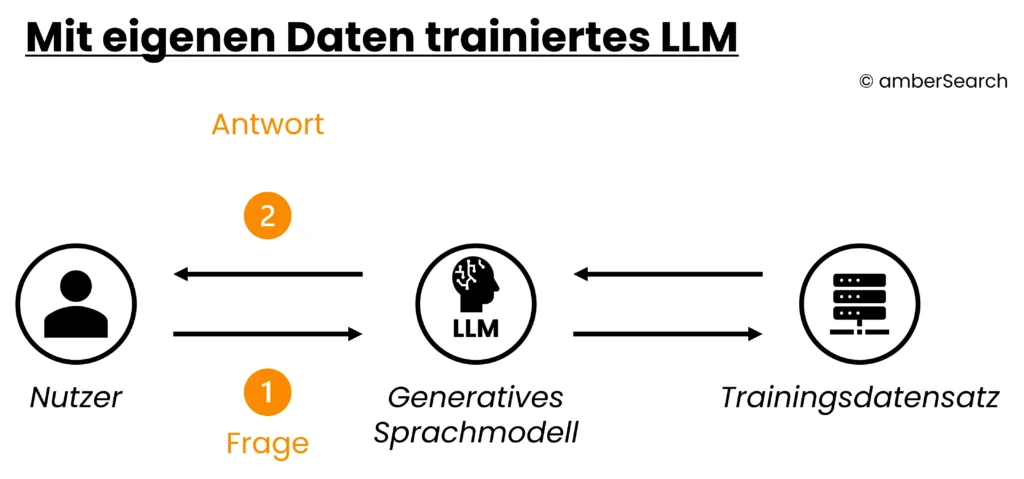
Darstellung der Architektur eines LLM’s, welches mit eigenen Daten trainiert wurde
Anstatt ein eigenes KI-Modell zu trainieren, können Unternehmen ein Open Source KI-Modell nachtrainieren bzw. Finetunen. Dafür müsste das Unternehmen eine hinreichende Menge an eigenen Daten zur Verfügung stellen und mit diesen das KI-Modell trainieren. Auch wenn man dadurch einen hohen Grad an Unabhängigkeit und Kontrolle erhält, ist das Training bzw. Finetuning nach wie vor sehr teuer. Zusätzlich besteht eine Herausforderung mit Halluzination und Zugriffsrechte. Des Weiteren werden sich verändernde Informationen im Unternehmen nicht ohne ein erneutes Training berücksichtigt.
Option 4: KI-Assistenten
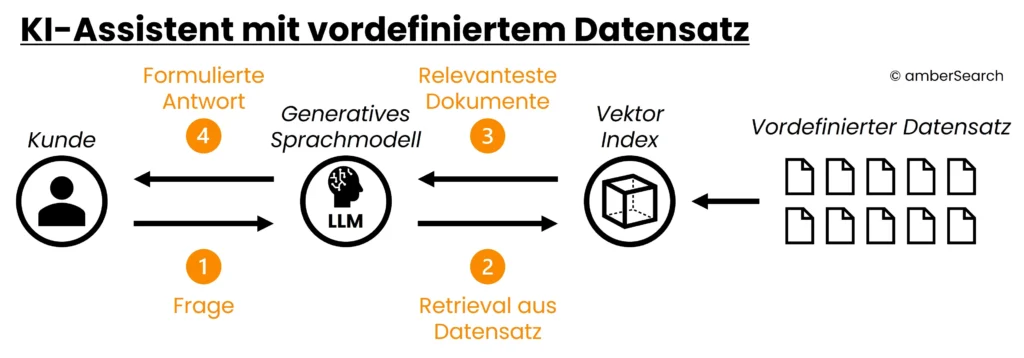
Darstellung der Architektur einer Generative AI Search bzw. eines KI-Agenten
Eine deutlich bessere Variante der Kombination von internen Daten mit generativer KI ist der Aufbau eines KI-Assistenten. Dafür muss auch hier wieder ein Datensatz als Grundlage definiert werden. Dies könnte zum Beispiel ein Export von Informationen zu einem bestimmten Thema sein. Aus diesen Daten wird dann ein Index aufgebaut. Hat ein Nutzer eine Frage, dann generiert der KI-Assistent eine Antwort nicht basierend auf den „Erlernten“ Informationen, sondern sucht zunächst im Index nach relevanten Informationen.
Diese Ergebnisse werden anschließend vom KI-Modell genutzt, um eine passende Antwort zu generieren. Dem KI-Modell wird also im Grunde genommen gesagt: „Der Nutzer hat Frage „X“ gestellt. Ergebnis 1, 2 und 3 passen inhaltlich gut zur Frage. Nutze die Inhalte dieser Ergebnisse, um die Frage des Nutzers zu beantworten.“. Der Vorteil ist, dass der Index leicht angepasst werden kann und somit sich ändernde Daten leicht abgebildet werden können. Zusätzlich wird die Problematik der Halluzination durch diesen Ansatz behoben. Der Nachteil ist, dass nach wie vor keine tiefe Integration mit bestehenden Daten existiert und Zugriffsrechte nicht berücksichtigt werden. Zusätzlich muss für jeden Anwendungsfall ein eigener KI-Assistenz aufgebaut werden. Somit verlieren Mitarbeitende schnell den Überblick. Die hier beschriebene Technik nennt sich Retrieval Augmented Generation.
Option 5: KI-Agenten bzw. generative AI Search
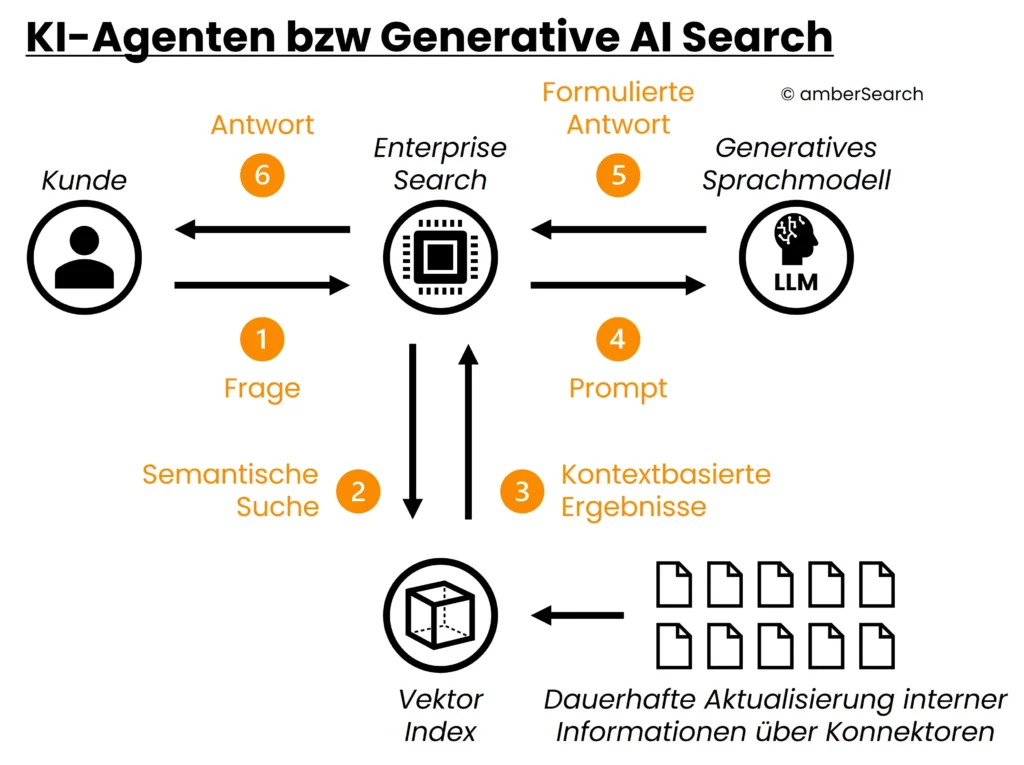
Darstellung der Architektur einer Generative AI Search bzw. eines KI-Agenten
Die letzte, aber auch nachhaltigste Ausbaustufe für KI im Unternehmen ist die Einführung von KI-Agenten bzw. generative AI Search. Da diese Kategorie noch relativ neu ist, hat sich hier noch keine eindeutige Definition herauskristallisiert und viele Unternehmen probieren sich, unter dieser Beschreibung zu positionieren, obwohl sie es nach unserer Definition nicht wären.
Um jedoch eine nachhaltige Integration mit internen Systemen hinzubekommen, werden so genannte Konnektoren benötigt. Diese Konnektoren können automatisch einen Index – unter Berücksichtigung der Zugriffsrechte – aufbauen und diesen kontinuierlich aktualisieren. So können sich auch verändernde Informationen abgebildet werden, in dem sie im Index aktualisiert bzw. gelöscht werden. Dadurch, dass man nun jedoch nicht mehr über kleine, ausgewählte Datensätze wie bei KI-Assistenten spricht, sondern quasi das ganze Unternehmenswissen indiziert wird, ist der Index unwesentlich größer.
Dies führt dazu, dass bei der Bearbeitung einer Anfrage zunächst eine leistungsstarke Suche über den Index muss, um die relevantesten Ergebnisse für das Retrieval Augmented Generation System zu nutzen. Für diesen Teil eignet sich besonders gut eine LLM-basierte Enterprise Search (unternehmensinterne Suchmaschine), da sie bereits Konnektoren zu den verschiedenen Systemen mitbringt und auf die Suche in großen Datenmengen spezialisiert ist.
Über eine Integration einer solchen Softwarelösung könnten alle Datensilos – unter Berücksichtigung der Zugriffsrechte – angebunden werden. Mit diesem technischen Ansatz könnte man alle internen Datensilos über eine KI-Lösung nachhaltig in die IT-Infrastruktur einbinden. Der Vorteil ist, dass über standardisierte Konnektoren eine einfache technische Integration (weniger als 4 Stunden) einer solchen Lösung möglich ist. Wie die Nutzeroberfläche für einen solchen Anwendungsfall aussehen kann, zeigt dieses Video:
Sicherheit & Datenschutz beim Einsatz von KI in Unternehmen
Dem Thema Sicherheit und Datenschutz möchten wir in diesem Abschnitt noch einen eigenen Abschnitt widmen. Für Unternehmen ist das über Jahre aufgebaute Know-How das, was am schwierigsten zu kopieren ist und dementsprechend ist dies besonders schützenwert. Zeitgleich ist der Einsatz von KI ohne eine Kombination mit internen Daten von begrenztem Vorteil.
Zurecht haben Unternehmen daher vorbehalte, wenn es darum geht, KI in Kombination mit internen Daten im Unternehmen einzusetzen. Zudem sind Kunden ihren Lieferanten, Kunden und Mitarbeitenden zum Datenschutz verpflichtet, was eine weitere Sorgfaltspflicht mit sich bringt.
Im deutschsprachigen Raum kursiert hartnäckig das Gerücht, dass alle Anbieter von Large Language Models (LLMs) die Eingabedaten der Nutzer zur Weiterentwicklung ihrer Modelle nutzen. Das stimmt nicht. Diese Praxis trifft nur auf die kostenlosen und öffentlichen Versionen von ChatGPT und ähnlichen Modellen zu. Bei der Nutzung von geschäftlichen Lizenzen ist die Verwendung von Eingabedaten für das Training der Modelle ausgeschlossen.
Daher sollten interessierte Unternehmen darauf achten, sich entsprechende Unterlagen wie technische und organisatorische Maßnahmen oder Serverstandorte erklären zu lassen und einen genauen Blick auf die Subunternehmen im Auftragsverarbeitungsvertrag zu legen. Um hier eine ausreichende Sicherheit zu gewährleisten, ist es empfehlenswert, KI-Tools zentral von der IT aus freizugeben bzw. zu steuern und Mitarbeitende nicht ihre eigenen Tools nutzen zu lassen. Dann ist es für Unternehmen nicht mehr nachvollziehbar, wo die eigenen Daten landen.
Rechtlich sicherer Einsatz von generativer KI im Unternehmen
Um KI-Lösungen im Unternehmen sicher einsetzen zu können, sollten einige Grundsätze beachtet werden. Welche das sind, das erklärt dieser Artikel.
Mit amberSearch haben wir eine Lösung gebaut, die komplett unabhängig von amerikanischen Anbietern funktioniert und bei unseren Kunden, die vom Mittelstand bis zum DAX-Konzern oder aber vom Maschinenbau bis hin zur KRITIS- und Pharmabranche reichen, komplett DSGVO-konform läuft.
Um interessierten Unternehmen ein besseres Gefühl für die Einführung von generativer KI zu geben, haben wir in der Vergangenheit ein Webinar zu diesem Thema durchgeführt. Das Webinar kann hier angesehen werden.
Einführung von KI und die Berücksichtigung von Mitarbeitenden
Um einen umfassenden Blick auf das Thema KI werfen zu können, sollte nicht nur die Technik, sondern auch die Mitarbeitenden mit ins Boot genommen werden. Viele Mitarbeitende haben sich bisher noch nicht mit KI beschäftigt, verstehen die Technologie nicht und glauben, basierend auf gefährlichem Halbwissen, dass KI uns irgendwann ersetzen wird. Hier gilt es, proaktiv zu kommunizieren und einen sicheren Rahmen zu setzen, in dem Mitarbeitende über KI lernen können und Erfahrungen sammeln können. Falls gewünscht, dann können wir gerne mit unserer Expertise unterstützen.
Um sicherzustellen, dass die Mitarbeitenden abgeholt werden, empfiehlt es sich, die in diesem Blogbeitrag empfohlenen Schritte zu berücksichtigen.
Wer nun angefixt ist und mehr über die praktischen To Do’s so wie den Best Practices für die Einführung einer generativen KI erfahren möchte, der sollte unseren White Paper „So geht eine erfolgreiche Einführung von generativer KI“. Dort werden auf über 16 Seiten notwendige Ressourcen so wie Umsetzungskonzepte erklärt. Das White Paper gibt es hier zum kostenlosen Download:
Schlusswort
In diesem Blogartikel haben wir viele Themen, die die Einführung von generativer KI mit internen Informationen berühren, beschrieben. Zurecht fragen sich Unternehmen, wie sie die Mehrwerte realisieren können und wo sie anfangen sollten. Wir hoffen, mit unserer Expertise einen ausreichend tiefen Einblick in dieses Thema gegeben haben zu können, so dass alle Punkte einmal abgebildet werden konnten. Auch wenn viele Unternehmen mit einer Integration von Option 1 starten bzw. gestartet haben, sind Option 4 oder 5 langfristig deutlich nachhaltiger. Das die Entwicklung einer Lösung, insbesondere wie unter Option 5 beschrieben aufgrund der Integrationskomplexität kein Fall für eine Eigenentwicklung ist, wissen die meisten Unternehmen.
Mit amberSearch haben wir bereits 2020 angefangen, eigene Retrieval-Modelle zu entwickeln und Konnektoren zu den verschiedenen Datensilos entwickelt. Dies hilft uns heute, das führende Unternehmen im Segment AI-Agents mit unternehmensinternen Daten zu sein. Kunden aus dem Mittelstand, DAX-Konzernen und zum Beispiel aus dem KRITIS oder Rüstungsbereich setzen auf unsere Lösung. Gerne helfen wir bei der Einführung und Umsetzung eines KI-Projekts.
Klingt spannend und Sie haben Interesse daran, uns näher kennenzulernen?
Dann buchen Sie sich hier einen unverbindlichen Ersttermin:
Wir freuen uns auf ein erstes Kennenlernen.