An enterprise search is typically used to search internal company content. However, the architecture of the search also influences the quality, the possibilities for further development and the future viability of the respective enterprise search system. This blog article explains the various architectures and breaks down the technical differences.
In particular, the three most common architectures of enterprise search solutions on the market will be analysed. These are federated search, keyword-based search and intelligent search based on large language models (LLM).
Table of Contents
How does a keyword-based search work?
In its original form, keyword-based searches are the simplest form of enterprise search. However, this technology experienced a real push, particularly in the 1990s and 2000s, as large amounts of data were manageable for the first time at this time. This works via an index that can contain metadata, URLs etc. in addition to information from the text. A keyword-based enterprise search works according to the following principle:
- First, all available data sources within the organisation are captured, including internal documents, databases, emails, intranet pages and more. This data is then indexed, which means that keywords and metadata are extracted from the documents and stored in a searchable database – the index.
- When a user submits a search query, they usually enter keywords or phrases to search for specific information. This search query is used by Enterprise Search to search for hits in the index.
- Various factors are taken into account to assess the relevance of the hits. These include factors such as the frequency of keywords in the document, the position of the keywords in the document and information from metadata.
- the most relevant documents are displayed in the search results, usually sorted according to the algorithmically calculated relevance. Users can browse the search results and access the documents that best meet their requirements.
Most keyword-based enterprise search solutions also offer filter and facet options that allow users to further narrow down the search results. This can be done, for example, by date, document type, author and other criteria. For some years now, keyword-based searches can be enhanced with technologies such as natural language processing to improve the results. For example, thesauri can be used to make normalisations of words and synonyms recognisable for the search engine. If you use these techniques in keyword-based searches, you will already have search algorithms that can deal with certain semantics.
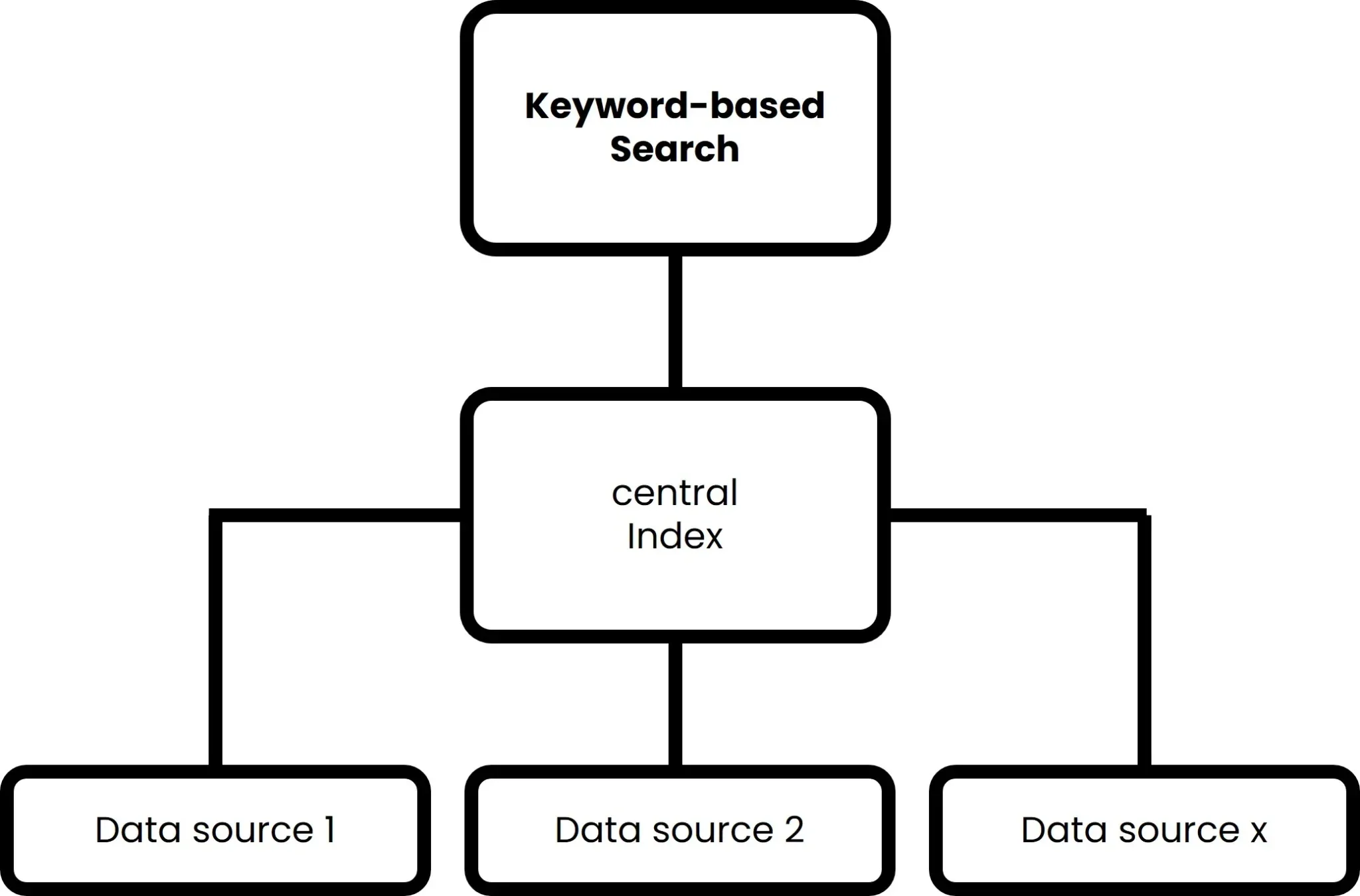
Figure 1 – Illustration of the logic of a keyword-based search
Challenge:
A keyword-based search is heavily dependent on the keywords used. Therefore, the user must already know what they are looking for in order to get relevant results. In addition, the context of the search input (e.g. who is searching, what did the user last search for, …) is not taken into account. This can lead to incomplete results being displayed. The quality of the results is also highly dependent on the quality of the synonyms entered. In addition, the index must first be created. Taking access rights into account is not entirely trivial – and this applies to all searches. Some providers offer consideration of access rights, while others restrict the search function exclusively to information that is accessible to everyone in the company.
Advantages:
The advantage of a keyword-based search for users is that they have been used to working with this (or a slightly modified syntax) for years in an internal company context. A keyword search combined with semantic elements can already achieve good results, depending on the use case.
How does a federated search work?
From today’s perspective, federated search is the simplest form of enterprise search. No separate index is created to enable cross-system searches. This is how a federated search works:
- First, a front end is developed for the user to enter a search.
- When a user enters a search, the words entered are passed one-to-one in the background to the search engines of all connected systems. Each search engine searches the respective system’s internal index using its own logic.
- The results found by the respective search engines are returned to the Federated Enterprise Search. This then mixes the results according to its own logic or simply displays the results sorted according to the various data sources.
The process is shown as an example in Figure 2:
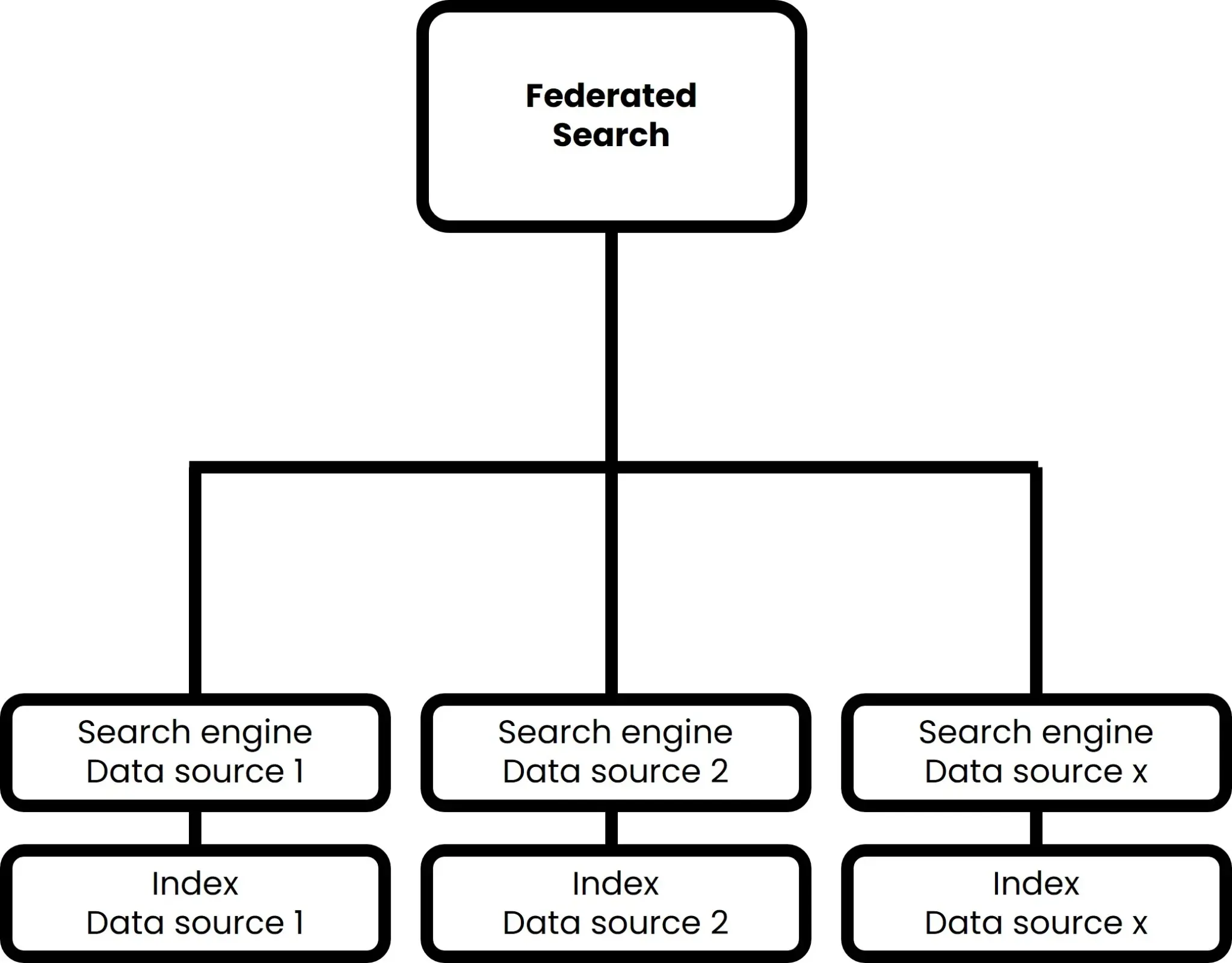
Figure 2: Illustration of the logic of a federated search
Challenges:
Because federated search depends on the quality of the search engines of the respective data sources, an enterprise search provider using this technology will never beat the quality of the results of the individual systems. The following applies: If the results of individual search engines are poor, then an enterprise search will not be able to improve them either.
The challenge is that a federated search does not take into account the syntax required for the respective search engine (e.g. email search vs. CRM vs. drive search).
Another challenge is that the search depends on the search speeds of the respective systems and cannot accelerate them.
Finally, matching the various user accounts is not entirely trivial. It must be ensured that only user results from the user’s perspective are shown and that no “administrator accounts” are used for the search that have access to everything – then the user would also see everything.
Advantages:
The advantage of federated search is that it has the simplest architecture and can be installed with relatively little (hardware) effort. In addition, you get all the results in one interface.
The Model Context Protocol
In 2024, Anthropic introduced the Model Context Protocol. The Model Context Protocol is a way to connect AI applications with corporate knowledge and is based on the same core principles as federated search. However, the MCP approach also has some weaknesses, which we explain in this blog article.
How does an intelligent search work?
Intelligent search, as we define it, works on the basis of Large Language Models (LLM), or transformer models to be precise. There are some providers that already describe NLP-combined, keyword-based search as intelligent, so when looking at different providers, a closer look is necessary to recognise the differences. Transformer models were first introduced at Google’s NIPS in 2017. Using artificial intelligence, transformer models offer a completely new technique for searching for information. In contrast to keyword-based searches, intelligent searches focus primarily on the semantic meaning of sentences or paragraphs instead of focussing exclusively on keywords. And this is how it works:
- Similar to a keyword-based search, a separate index is also created for the intelligent search. However, the information is not only stored in a simple database, but in so-called vector embeddings. This means that information is stored on the basis of its semantic meaning. This is done using the embedding generator shown in Figure 3. In addition (at least with amberSearch), the vector-based index is partially supplemented by a classic index.
- When a user submits a search query, they can either enter keywords or questions in natural language. The search query is then also converted into a vector embedding so that the semantic meaning can be understood.
- The vector embeddings found are analysed by the search software and the results are matched based on various factors such as the relevance of the content. Not only exact matches are matched, but also related concepts and topics (see Figure 4).
The process is illustrated in Figure 3:
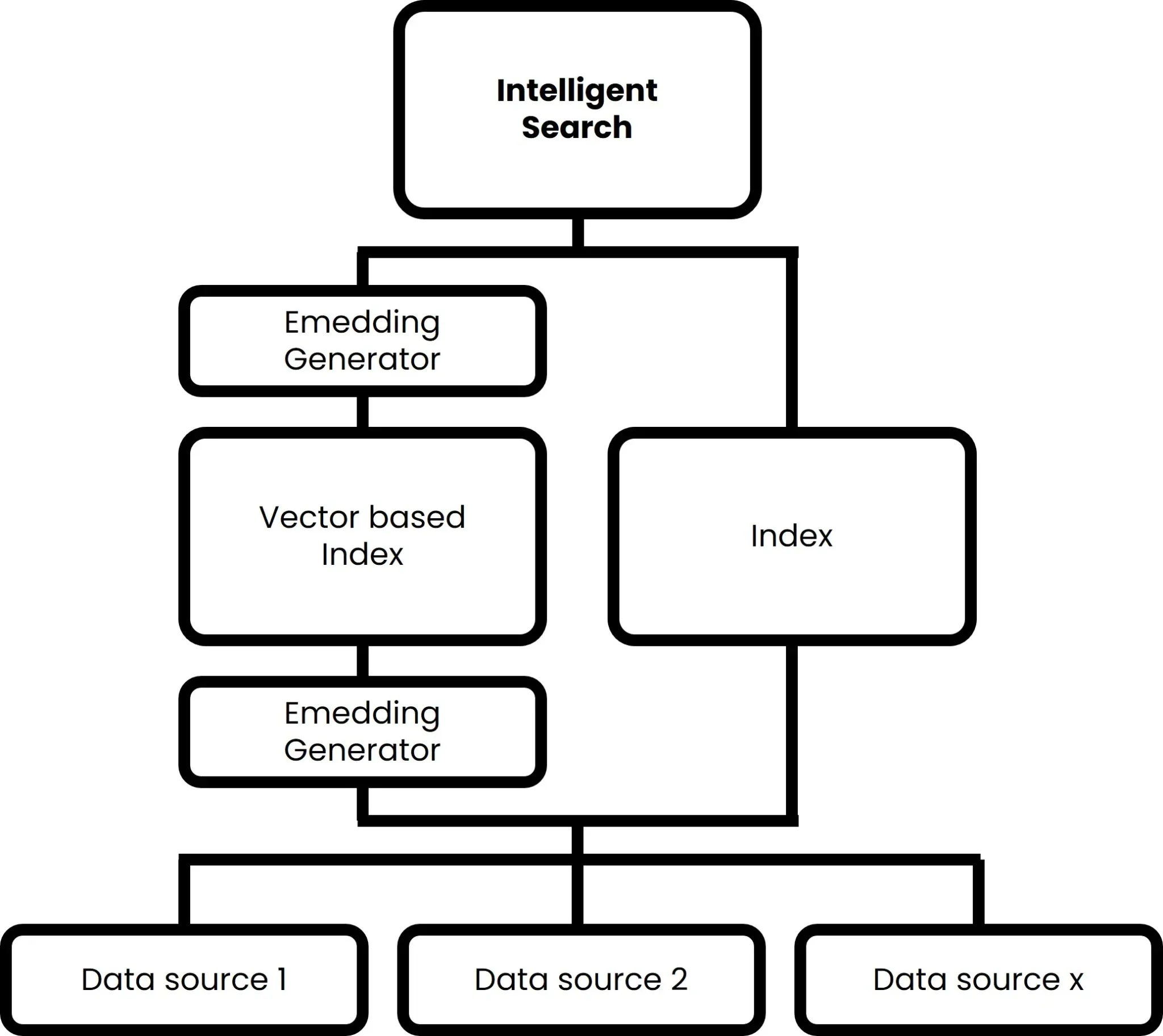
Figure 3: Illustration of the logic of an intelligent search
Challenges:
Because the results are evaluated using an AI model, the use of an intelligent search is more computationally intensive and requires more powerful servers than the other techniques presented. In addition, a great deal of expertise is required to set up such a system and optimally coordinate the various steps.
Advantages:
The results are significantly less dependent on the type of search query. The technology used means that the content intended by the user can be addressed in particular. In addition, a semantic search works independently of the language, i.e. it is possible to search in different languages at the same time. Due to the new search technology, no loss of speed is to be expected as with older keyword-based searches. The vector-based index can also be used to map multimedia content such as images, videos, 3D models or audio files, meaning that significantly more content can be searched than just text content. The following example illustrates the search logic of an intelligent search based on LLMs:
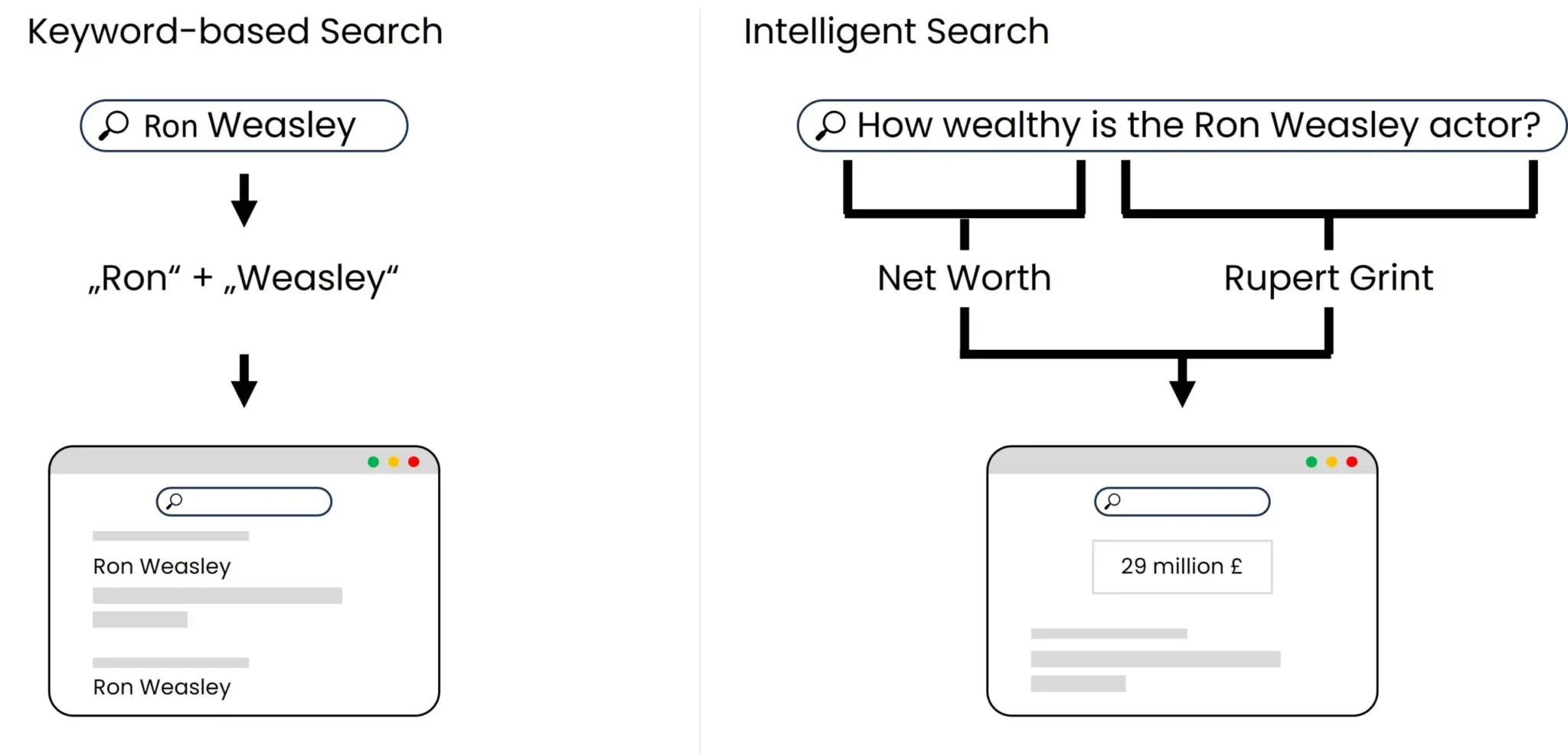
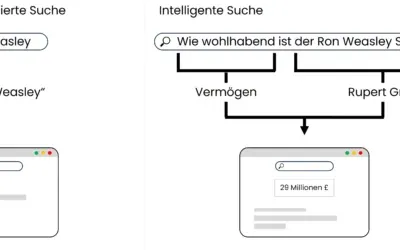
Figure 4: Comparison of search logic keyword-based search vs. intelligent search
Figure 4 shows the differences between the search logic of a keyword-based search and an intelligent search. The keyword-based search is primarily concerned with the frequency and positioning of certain words, while the semantic search on the right is primarily concerned with understanding the content.
Use of an intelligent search in amberSearch
We at amberSearch recognised the potential of semantic search back in 2020. In 2020, we therefore developed the most efficient German-language LLM at the time of publication and made it open source. Building on this, we developed a multi-lingual passage reranking model, which has received well over 200,000 downloads to date and has been categorised as the most efficient AI model of its kind in various papers (see sources in our blog post Retrieval Augmented Generation). Internally, we are now several iterations further along, but the current download figures also speak in favour of the quality of the model. The early use of this technology has enabled us to be one of the first German companies to build up expertise in this area. We have used this expertise to bring this technology to market maturity in our amberSearch product.
Getting to know the basics of introducing an intelligent system
The introduction of such software (sometimes in combination with generative AI) is not as complex as it may seem at first. To get a better feel for the implementation process, we have written a blog article on the topic of introducing generative AI. We have also uploaded a white paper on this topic on our website under “Resources”.
Further development of the intelligent search at amberSearch
With amberSearch as the basis, we have developed our cross-system copilot amberAI. This allows us to offer our customers a co-pilot that is not exclusively focussed on one software ecosystem, but truly works across all systems:
Over the next few months and years, a number of other exciting functions will follow on from this.
Further notes
The aim of this blog article is to explain the basic functions of various search technologies and to list the advantages and disadvantages. We would also like to give an initial impression of the technical limitations. Different providers develop their systems differently based on these approaches. One major point, for example, is the consideration of access rights. There are providers that only search existing information for all employees, as access rights cannot be mapped via their architecture. With amberSearch, on the other hand, we have decided to control access rights via single sign-on (SSO) or the Active Directory in order to make user administration as easy as possible for IT administrators and at the same time to be able to offer a truly comprehensive search engine.
Another way of making internal expertise accessible to employees, which has been discussed less in this blog article, is to train your own AI model. However, as we already have several blog articles [Should you train large language models with your own data?, What is retrieval augmented generation?] on our website, we have not gone into this topic in any depth in this article.